本文是丰亚东讲师在2021 ArchSummit 全球架构师峰会中「如何系统性治理 iOS 稳定性问题」的分享全文,公众号后台回复“AS”获取分享完整 PPT。
首先做一下自我介绍:我是丰亚东,2016 年 4 月加入字节跳动,先后负责今日头条 App 的工程架构、基础库和体验优化等基础技术方向。2017 年 12 月至今专注在 APM 方向,从 0 到 1 参与了字节跳动 APM 中台的建设,服务于字节的全系产品,目前主要负责 iOS 端的性能稳定性监控和优化。
本次分享主要分为四大章节,分别是:1.稳定性问题分类;2.稳定性问题治理方**;3.疑难问题归因;4.总结回顾。其中第三章节「疑难问题归因」是本次分享的重点,大概会占到60%的篇幅。
一、稳定性问题分类
在讲分类之前,我们先了解一下背景:大家都知道对于移动端应用而言,闪退是用户能遇到的最严重的 bug,因为在闪退之后用户无法继续使用产品,那么后续的用户留存以及产品本身的商业价值都无从谈起。
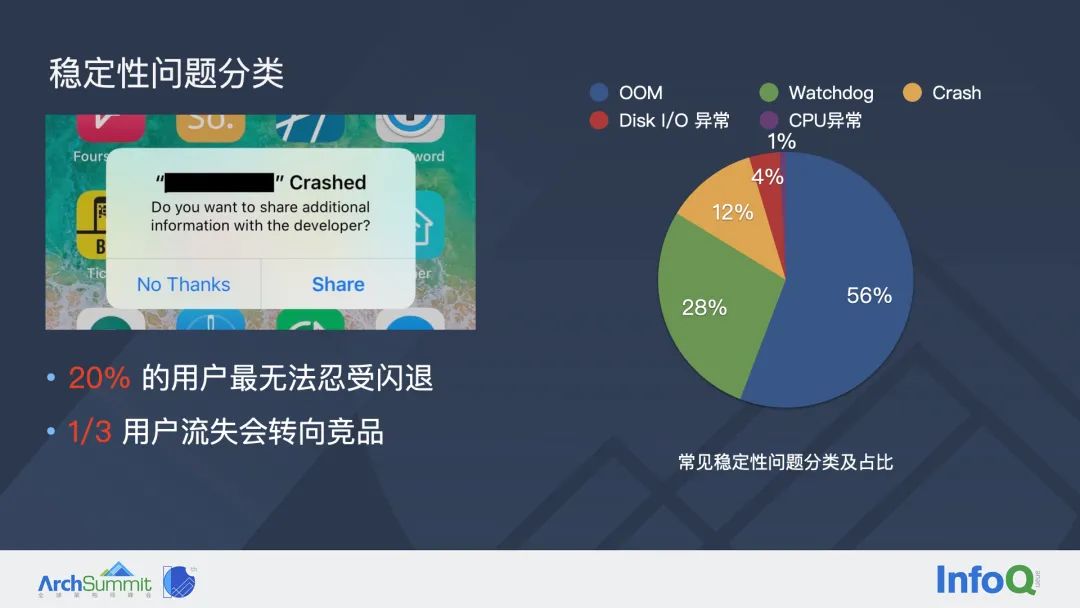
这里有一些数据想和大家分享:有 20% 的用户在使用移动端产品的时候,最无法忍受的问题就是闪退,这个比例仅次于不合时宜的广告;在因为体验问题流失的用户中,有 1/3 的用户会转而使用竞品,由此可见闪退问题是非常糟糕和严重的。
字节跳动作为拥有像抖音、头条等超大量级 App 的公司,对稳定性问题是非常重视的。过去几年,我们在这方面投入了非常多的人力和资源,同时也取得了不错的治理成果。过去两年抖音、头条、飞书等 App 的异常崩溃率都有 30% 以上的优化,个别产品的部分指标甚至有 80% 以上的优化。
通过上图中右侧的饼状图可以看出:我们以 iOS 平台为例,根据稳定性问题不同的原因,将已知稳定性问题分成了这五大类,通过占比从高到低排序:第一大类是 OOM ,就是内存占用过大导致的崩溃,这个比例能占到 50% 以上;其次是 Watchdog,也就是卡死,类比于安卓中的 ANR;再次是普通的 Crash;最后是磁盘 IO 异常和 CPU 异常。
看到这里大家心里可能会有一个疑问:字节跳动究竟做了什么,才取得了这样的成果?接下来我会将我们在稳定性治理方面沉淀的方**分享给大家。
二、稳定性问题治理的方**
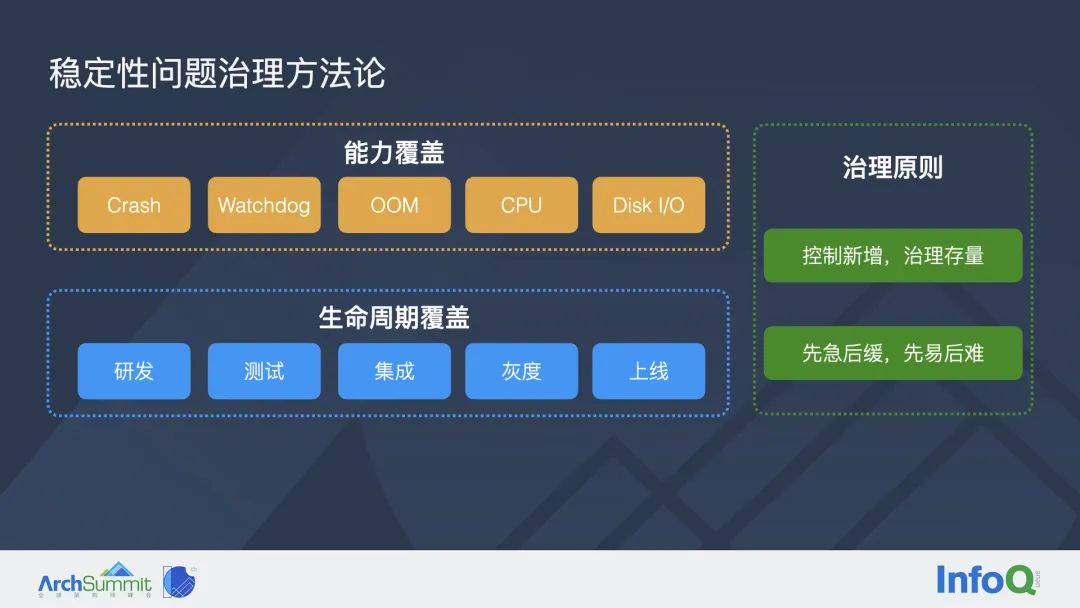
首先我们认为在稳定性问题治理方面,从监控平台侧视角出发,最重要的就是要有完整的能力覆盖,比如针对上一章节中提到所有类型的稳定性问题,监控平台都应该能及时准确的发现。
另外是从业务研发同学的视角出发:稳定性问题治理这个课题,需要贯穿到软件研发的完整生命周期,包括需求研发、测试、集成、灰度、上线等,在上述每个阶段,研发同学都应该重视稳定性问题的发现和治理。
上图中右侧是我们总结的两条比较重要的治理原则:
第一条是控制新增,治理存量。一般来说新增的稳定性问题可能是一些容易爆发的问题,影响比较严重。存量问题相对来说疑难的问题居多,修复周期较长。
第二条比较容易理解:先急后缓,先易后难。我们应该优先修复那些爆发的问题以及相对容易解决的问题。
如果我们将软件研发周期聚焦在稳定性问题治理这个方向上,又可以抽象出以下几个环节:
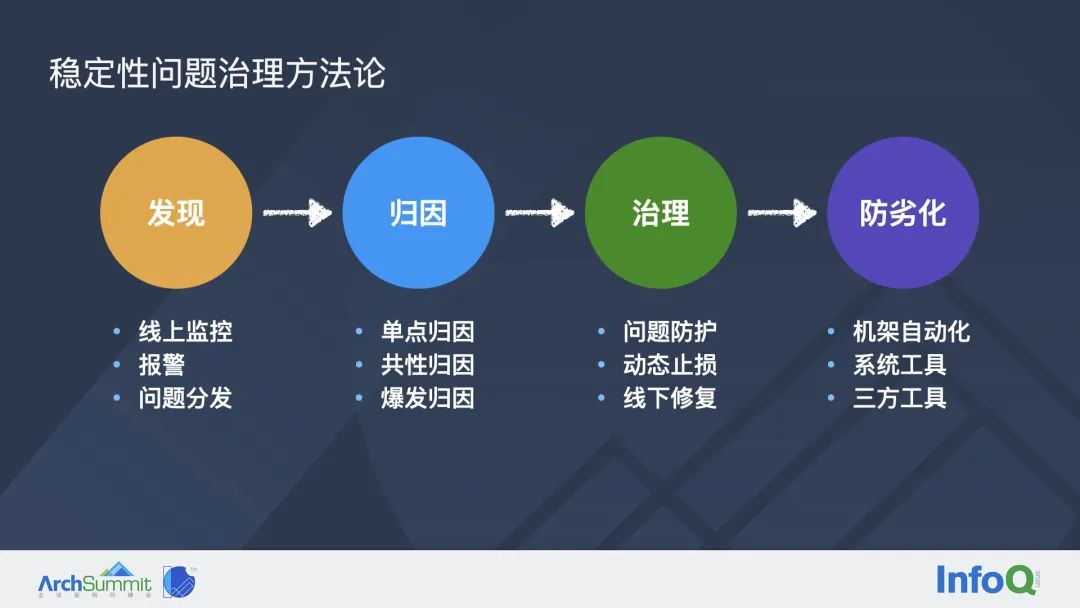
首先第一个环节是问题发现:当用户在线上遇到任何类型的闪退,监控平台都应该能及时发现并上报。同时可以通过报警以及问题的自动分发,将这些问题第一时间通知给开发者,确保这些问题能够被及时的修复。
第二个阶段是归因:当开发者拿到一个稳定性问题之后,要做的第一件事情应该是排查这个问题的原因。根据一些不同的场景,我们又可以把归因分为单点归因、共性归因以及爆发问题归因。
当排查到问题的原因之后,下一步就是把这个问题修复掉,也就是问题的治理。在这里我们有一些问题治理的手段:如果是在线上阶段,我们首先可以做一些问题防护,比如网易几年前一篇文章提到的基于 OC Runtime 的线上 Crash 自动修复的方案大白,基于这种方案我们可以直接在线上做 Crash 防护;另外由于后端服务上线导致的稳定性问题爆发,我们可以通过服务的回滚来做到动态止损。除了这两种手段之外,更多的场景还是需要研发在线下修复 native 代码,再通过发版做彻底的修复。
最后一个阶段也是最近几年比较火的一个话题,就是问题的防劣化。指的是需求从研发到上线之间的阶段,可以通过机架的自动化单元测试/UI自动化测试,以及研发可以通过一些系统工具,比如说 Xcode 和 Instruments,包括一些第三方工具,比如微信开源的 MLeaksFinder 去提前发现和解决各类稳定性问题。
如果我们想把稳定性问题治理做好的话,需要所有研发同学关注上述每一个环节,才能达到最终的目标。可是这么多环节我们的重点究竟在哪里呢?从字节跳动的问题治理经验来看,我们认为最重要的环节是第二个——线上的问题的归因。因为通过内部的统计数据发现:线上之所以存在长期没有结论,没有办法修复的问题,主要还是因为研发并没有定位到这些问题的根本原因。所以下一章节也是本次分享的重点:疑难问题归因。
三、疑难问题归因
我们根据开发者对这些问题的熟悉程度做了一下排序,分别是:Crash、Watchdog、OOM 和 CPU&Disk I/O。每一类疑难问题我都会分享这类问题的背景和对应的解决方案,并且会结合实战案例演示各种归因工具究竟是如何解决这些疑难问题的。
3.1 第一类疑难问题 —— Crash
上图中左侧这张饼状图是我们根据 Crash 不同的原因,把它细分成四大类:包括 Mach 异常、 Unix Signal 异常、OC 和 C++ 语言层面上的异常。其中比例最高的还是 Mach 异常,其次是 Signal 异常,OC 和 C++ 的异常相对比较少。
为什么是这个比例呢?
大家可以看到右上角有两个数据。第一个数据是微软发布的一篇文章,称其发布的 70% 以上的安全补丁都是内存相关的错误,对应到 iOS 平台上就是 Mach 异常中的非法地址访问,也就是 EXC_BAD_ACCESS。内部统计数据表明,字节跳动线上 Crash 有 80% 是长期没有结论的,在这部分 Crash 当中,90% 以上都是 Mach 异常或者 Signal 异常。
看到这里,大家肯定心里又有疑问了,为什么有这么多 Crash 解决不了?究竟难在哪里?我们总结了几点这些问题归因的难点:
-
首先不同于 OC 和 C++ 的异常,可能开发者拿到的崩溃调用栈是一个纯系统调用栈,这类问题显然修复难度是非常大的;
-
另外可能有一部分Crash是偶发而不是必现的问题,研发同学想在线下复现问题是非常困难的,因为无法复现,也就很难通过 IDE 调试去排查和定位这些问题;
-
另外对于非法地址访问这类问题,崩溃的调用栈可能并不是第一现场。这里举一个很简单的例子:A业务的内存分配溢出,踩到了B业务的内存,这个时候我们认为 A 业务应该是导致这个问题的主要原因,但是有可能B业务在之后的某一个时机用到了这块内存,发生了崩溃。显然这种问题实际上是 A 业务导致的,最终却崩在了 B 业务的调用栈里,这就会给开发者排查和解决这个问题带来非常大的干扰。
看到这里大家可能心里又有问题:既然这类问题如此难解,是不是就完全没有办法了呢?其实也并不是,下面我会分享字节内部两个解决这类疑难问题非常好用的归因工具。
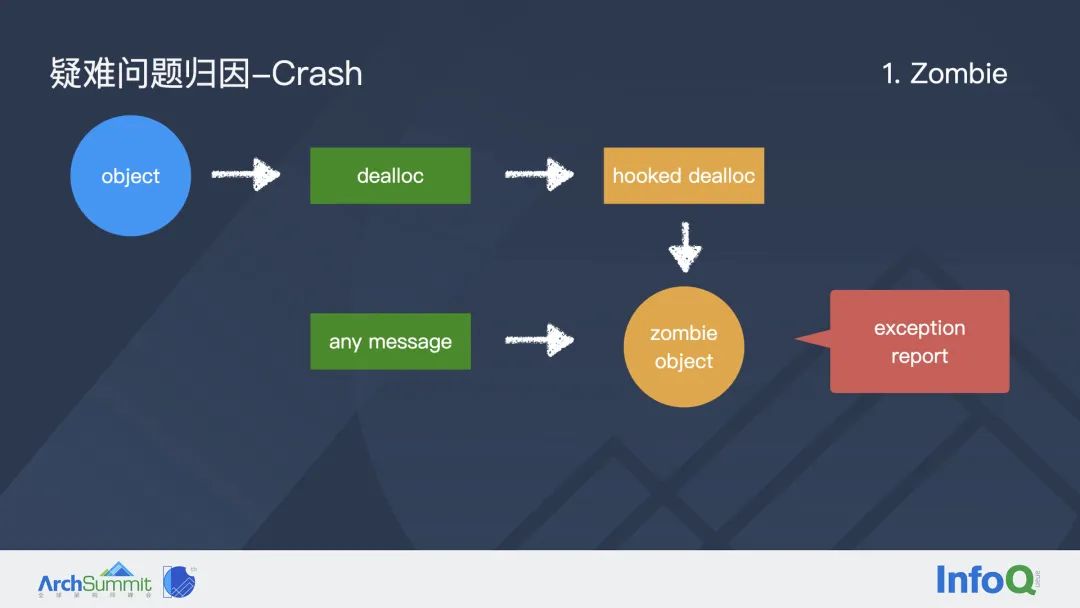
首先第一个是 Zombie 检测,大家如果用过 Xcode 的 Zombie 监控,应该对这个功能比较熟悉。如果我们在调试之前打开了 Zombie Objects 这个开关,在运行的时候如果遇到了 OC 对象野指针造成的崩溃,Xcode 控制台中会打印出一行日志,它会告诉开发者哪个对象在调用什么消息的时候崩溃了。
这里我们再解释一下 Zombie 的定义,其实非常简单,指的是已经释放的 OC 对象。
Zombie 监控的归因优势是什么呢?首先它可以直接定位到问题发生的类,而不是一些随机的崩溃调用栈;另外它可以提高偶现问题的复现概率,因为大部分偶现问题可能跟多线程的运行环境有关,如果我们能把一个偶现问题变成必现问题的话,那么开发者就可以借助 IDE 和调试器非常方便地排查问题。但是这个方案也有自己的适用范围,因为它的底层原理基于 OC 的 runtime 机制,所以它仅仅适用于 OC 对象野指针导致的内存问题。
这里再和大家一起回顾一下 Zombie 监控的原理:首先我们会 hook 基类 NSObject 的 dealloc 方法,当任意 OC 对象被释放的时候,hook 之后的那个 dealloc 方法并不会真正的释放这块内存,同时将这个对象的 ISA 指针指向一个特殊的僵尸类,因为这个特殊的僵尸类没有实现任何方法,所以这个僵尸对象在之后接收到任何消息都会 Crash,与此同时我们会将崩溃现场这个僵尸对象的类名以及当时调用的方法名上报到后台分析。
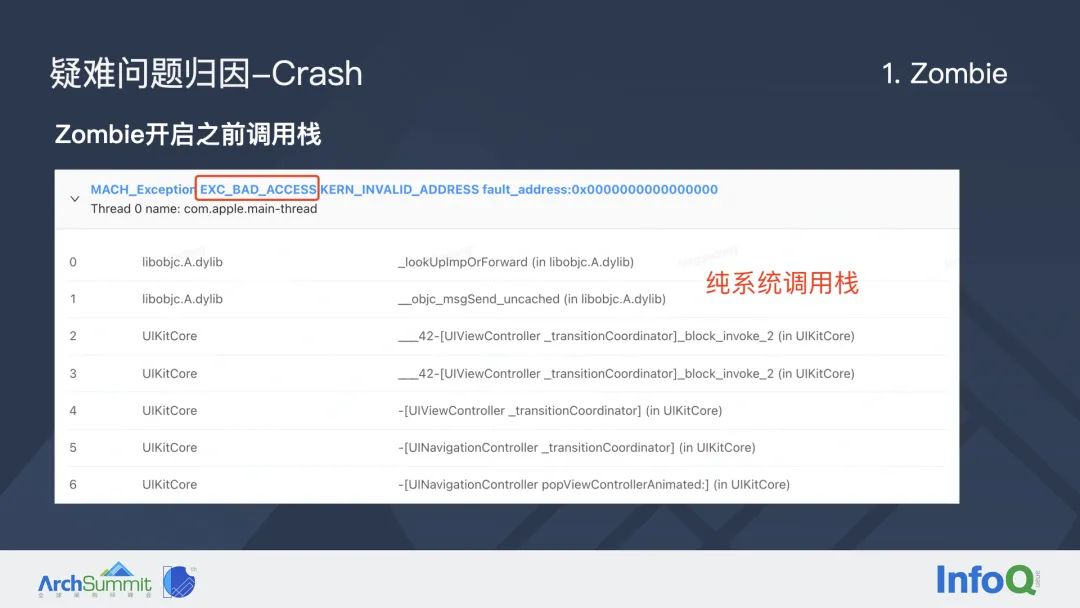
这里是字节的一个真实案例:这个问题是飞书在某个版本线上 Top 1 的 Crash,当时持续了两个月没有被解决。首先大家可以看到这个崩溃调用栈是一个纯系统调用栈,它的崩溃类型是非法地址访问,发生在视图导航控制器的一次转场动画,可能开发者一开始看到这个崩溃调用栈是毫无思路的。
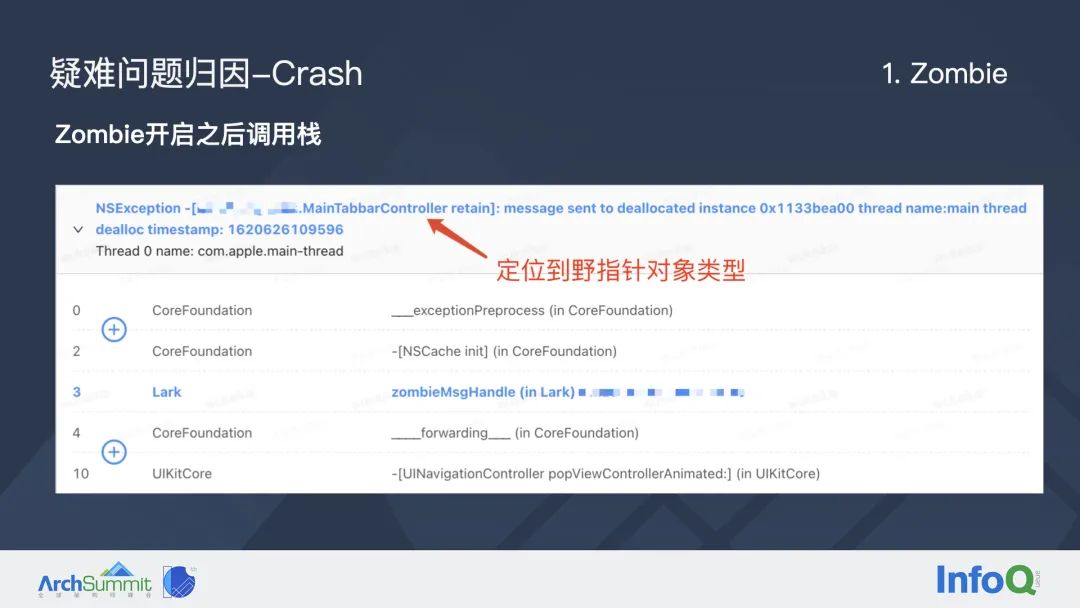
那么我们再看 Zombie 功能开启之后的崩溃调用栈:这个时候报错信息会更加丰富,可以直接定位到野指针对象的类型,是 MainTabbarController 对象在调用 retain 方法的时候发生了 Crash。
看到这里大家肯定有疑问了,MainTabbarController 一般而言都是首页的根视图控制器,理论上在整个生命周期内不应该被释放。为什么它变成了一个野指针对象呢?可见这样一个简单的报错信息,有时候还并不足以让开发者定位到问题的根本原因。所以这里我们更进一步,扩展了一个功能:将 Zombie 对象释放时的调用栈信息同时上报上来。

大家看倒数第二行,实际上是一段飞书的业务代码,是视图导航控制器手势识别的代理方法,这个方法在调用的时候释放了 MainTabbarController。因为通过这个调用栈找到了业务代码的调用点,所以我们只需要对照源码去分析为什么会释放 TabbarController,就可以定位到这个问题的原因。
上图中右侧是简化之后的源码(因为涉及到代码隐私问题,所以通过一段注释代替)。历史上为了解决手势滑动返回的冲突问题,在飞书视图导航控制器的手势识别代理方法中写了一段 trick 代码,正是这个 trick 方案导致了首页视图导航控制器被意外释放。
排查到这里,我们就找到了问题的根本原因,修复的方案也就非常简单了:只要下掉这个 trick 方案,并且依赖导航控制器的原生实现来决定这个手势是否触发就解决了这个问题。
刚才也提到:Zombie 监控方案是有一些局限的,它仅适用于 OC 对象的野指针问题。大家可能又会有疑问:C 和 C++ 代码同样可能会出现野指针问题,在 Mach 异常和 Signal 异常中,除了内存问题之外,还有很多其他类型的异常比如 EXC_BAD_INSTRUCTION和SIGABRT。那么其他的疑难问题我们又该怎么解决呢?这里我们给出了另外一个解决方案 —— Coredump。

这个先解释一下什么是 Coredump:Coredump 是由 lldb 定义的一种特殊的文件格式,Coredump 文件可以还原 App 在运行到某一时刻的完整运行状态(这里的运行状态主要指的是内存状态)。大家可以简单的理解为:Coredump文件相当于在崩溃的现场打了一个断点,并且获取到当时所有线程的寄存器信息,栈内存以及完整的堆内存。
Coredump 方案它的归因优势是什么呢?首先因为它是 lldb 定义的文件格式,所以它天然支持 lldb 的指令调试,也就是说开发者无需复现问题,就可以实现线上疑难问题的事后调试。另外因为它有崩溃时现场的所有内存信息,这就为开发者提供了海量的问题分析素材。
这个方案的适用范围比较广,可以适用于任意 Mach 异常或者 Signal 异常问题的分析。

下面也带来一个线上真实案例的分析:当时这个问题出现在字节的所有产品中,而且在很多产品中的量级非常大,排名Top 1 或者 Top 2,这个问题在之前两年的时间内都没有被解决。
大家可以看到这个崩溃调用栈也全是系统库方法,最终崩溃在 libdispatch 库中的一个方法,异常类型是命中系统库断言。
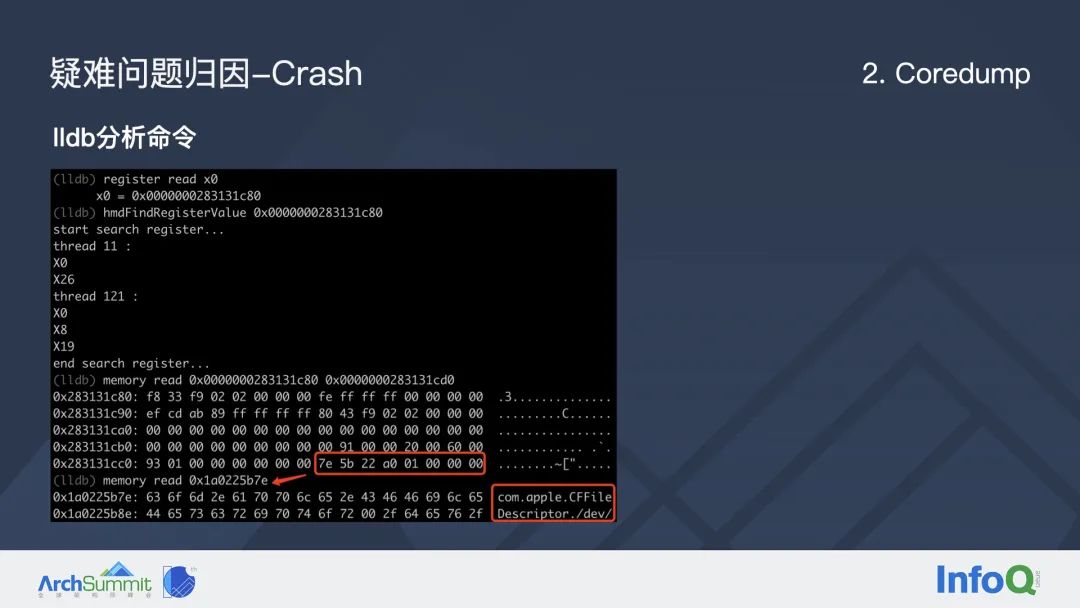
我们将这次崩溃的 Coredump 文件上报之后,用前面提到的 lldb 调试指令去分析,因为拥有崩溃时的完整内存状态,所以我们可以分析所有线程的寄存器和栈内存等信息。
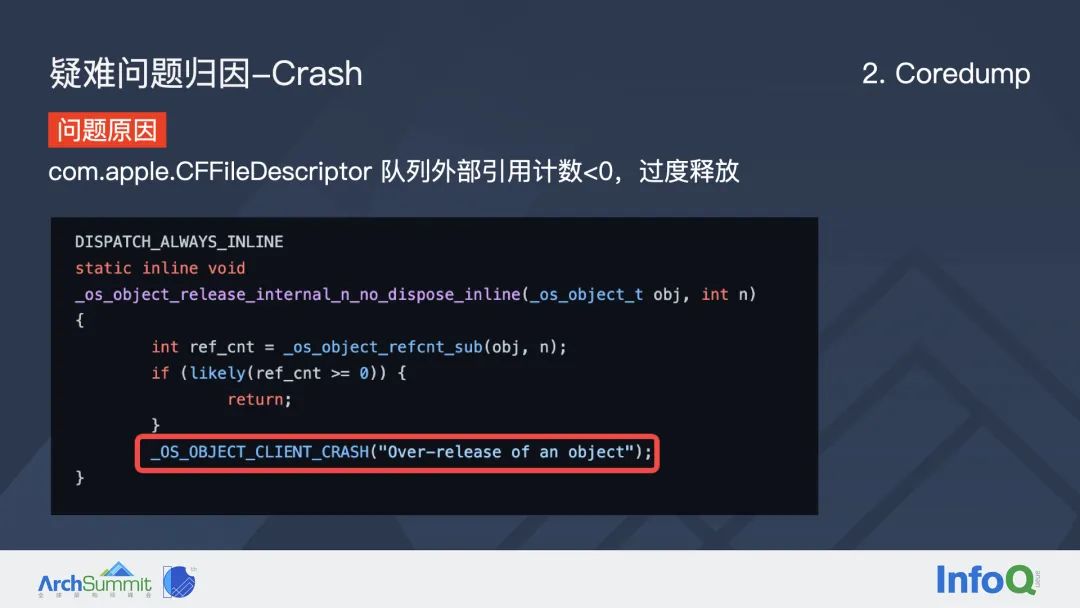
这里最终我们分析出:崩溃线程的 0 号栈帧(第一行调用栈),它的 x0 寄程器实际上就是 libdispatch 中定义的队列结构体信息。在它起始地址偏移 0x48 字节的地方,也就是这个队列的 label 属性(可以简单理解为队列的名字)。这个队列的名字对我们来说是至关重要的,因为要修复这个问题,首先应该知道究竟是哪个队列出现了问题。通过 memory read 指令我们直接读取这块内存的信息,最终发现它是一个 C 的字符串,名字叫 com.appple.CFFileDescriptor,这个信息非常关键。我们在源码中全局搜索这个关键字,最终发现这个队列是在字节底层的网络库中创建的,这也就能解释为什么字节所有产品都有这个崩溃了。
最终我们和网络库的同学一起排查,同时结合 libdispatch 的源码,定位到这个问题的原因是 GCD 队列的外部引用计数小于0,存在过度释放的问题,最终命中系统库断言导致崩溃。
排查到问题之后,解决方案就比较简单了:我们只需要在这个队列创建的时候,使用 dispatch_source_create 的方式去增加队列的外部引用计数,就能解决这个问题。和维护网络库的同学沟通后,确认这个队列在整个 App 的生命周期内不应该被释放。这个问题最终解决的收益是直接让字节所有产品的 Crash 率降低了8%。
我们进入疑难问题中的第二类问题 —— Watchdog 也就是卡死。
上图中左侧是我在微博上截的两张图,是用户在遇到卡死问题之后的抱怨。可见卡死问题对用户体验的伤害还是比较大的。那么卡死问题它的危害有哪些呢?
首先卡死问题通常发生于用户打开 App 的冷启动阶段,用户可能等待了10 秒什么都没有做,这个 App 就崩溃了,这对用户体验的伤害是非常大的。另外我们线上监控发现,如果没有对卡死问题做任何治理的话,它的量级可能是普通 Crash 的 2-3 倍。另外现在业界普遍监控 OOM 崩溃的做法是排除法,如果没有排除卡死崩溃的话,相应的就会增加 OOM 崩溃误判的概率。
卡死类问题的归因难点有哪些呢?首先基于传统的方案——卡顿监控:认为主线程无响应时间超过3秒~5秒之后就是一次卡死,这种传统的方案非常容易误报,至于为什么误报,我们下一页中会讲到。另外卡死的成因可能非常复杂,它不一定是单一的问题:主线程的死锁、锁等待、主线程 IO 等原因都有可能造成卡死。第三点是死锁问题是一类常见的导致卡死问题的原因。传统方案对于死锁问题的分析门槛是比较高的,因为它强依赖开发者的经验,开发者必须依靠人工的经验去分析主线程到底跟哪个或者哪些线程互相等待造成死锁,以及为什么发生死锁。
大家可以看到这是基于传统的卡顿方案来监控卡死,容易发生误报。为什么呢?图中绿色和红色的部分是主线程的不同耗时阶段。假如主线程现在卡顿的时间已经超过了卡死阈值,刚好发生在图中的第5个耗时阶段,我们在此时去抓取主线程调用栈,显然它并不是这次耗时的最主要的原因,问题其实主要发生在第4个耗时阶段,但是此时第4个耗时阶段已经过去了,所以会发生一次误报,这可能让开发者错过真正的问题。
针对以上提到的痛点,我们给出了两个解决方案:首先在卡死监控的时候可以多次抓取主线程调用栈,并且记录每次不同时刻主线程的线程状态,关于线程状态包括哪些信息,下一页中会提到。
另外我们可以自动识别出死锁导致的卡死问题,将这类问题标识出来,并且可以帮助开发者自动还原出各个线程之间的锁等待关系。
首先是第一个归因工具——线程状态,这张图是主线程在不同时刻调用栈的信息,在每个线程名字后面都有三个 tag ,分别指的是三种线程的状态,包括当时的线程 CPU 占用、线程运行状态和线程标志。
上图中右侧是线程的运行状态和线程标志的解释。当看到线程状态的时候,我们主要的分析思路有两种:第一种,如果看到主线程的 CPU 占用为 0,当前处于等待的状态,已经被换出,那我们就有理由怀疑当前这次卡死可能是因为死锁导致的;另外一种,特征有所区别,主线程的 CPU 占用一直很高 ,处于运行的状态,那么就应该怀疑主线程是否存在一些死循环等 CPU 密集型的任务。
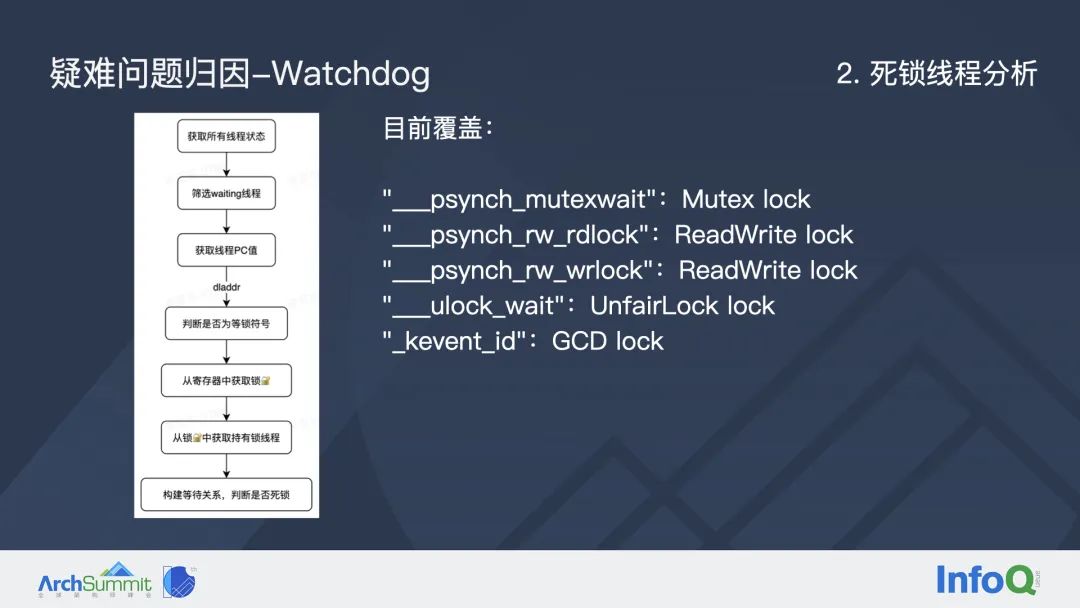
第二个归因工具是死锁线程分析,这个功能比较新颖,所以首先带领大家了解一下它的原理。基于上一页提到的线程状态,我们可以在卡死时获取到所有线程的状态并且筛选出所有处于等待状态的线程,再获取每个线程当前的 PC 地址,也就是正在执行的方法,并通过符号化判断它是否是一个锁等待的方法。
上图中列举了目前我们覆盖到的一些锁等待方法,包括互斥锁、读写锁、自旋锁、 GCD 锁等等。每个锁等待的方法都会定义一个参数,传入当前锁等待的信息。我们可以从寄存器中读取到这些锁等待信息,强转为对应的结构体,每一个结构体中都会定义一个线程id的属性,表示当前这个线程正在等待哪个线程释放锁。对每一个处于等待状态的线程完成这样一系列操作之后,我们就能够完整获得所有线程的锁等待关系,并构建出锁等待关系图。
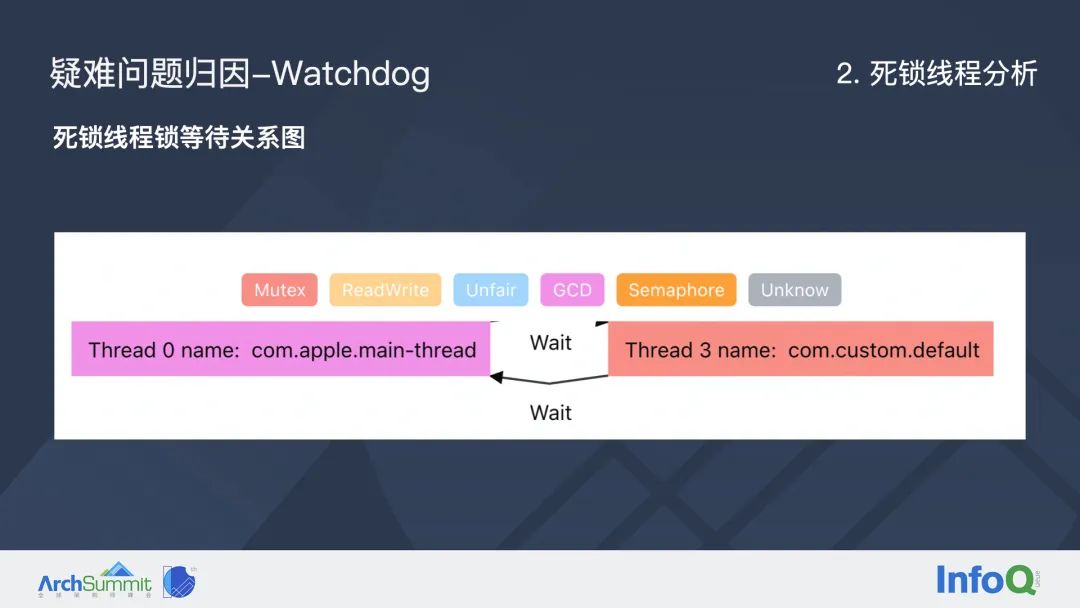
通过上述方案,我们可以自动识别出死锁线程。假如我们能判断 0 号线程在等待 3 号线程释放锁, 同时3 号线程在等待0号线程释放锁,那么显然就是两个互相等待最终造成死锁的线程。
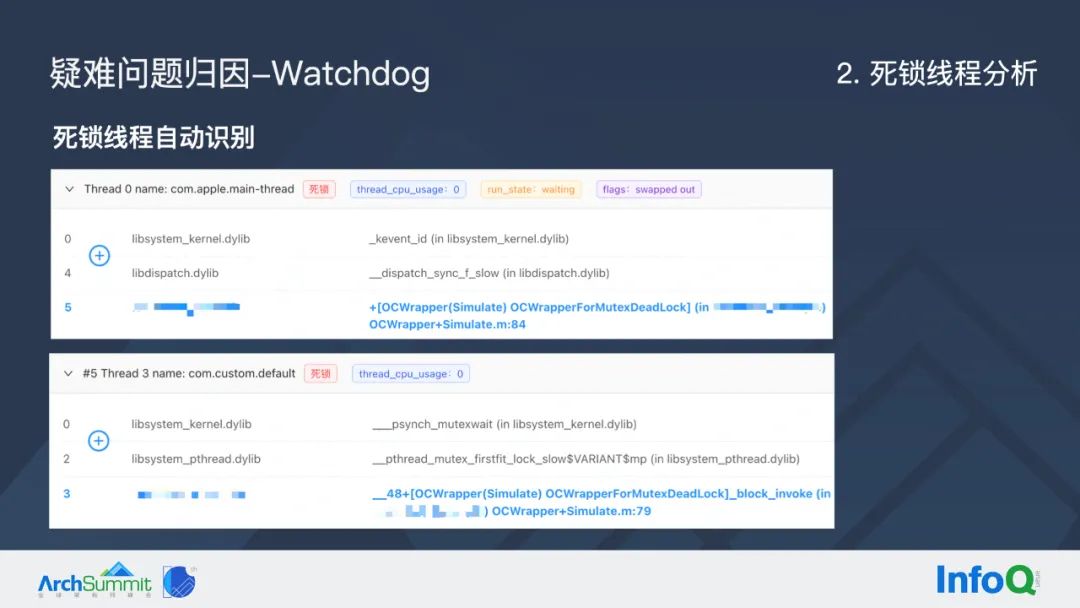
大家可以看到这里主线程我们标记为死锁,它的 CPU 占用为 0,状态是等待状态,而且已经被换出了,和我们之前分析线程状态的方**是吻合的。
通过这样的分析之后,我们就能够构建出一个完整的锁等待关系图,而且无论是两个线程还是更多线程互相等待造成的死锁问题,都可以自动识别和分析。
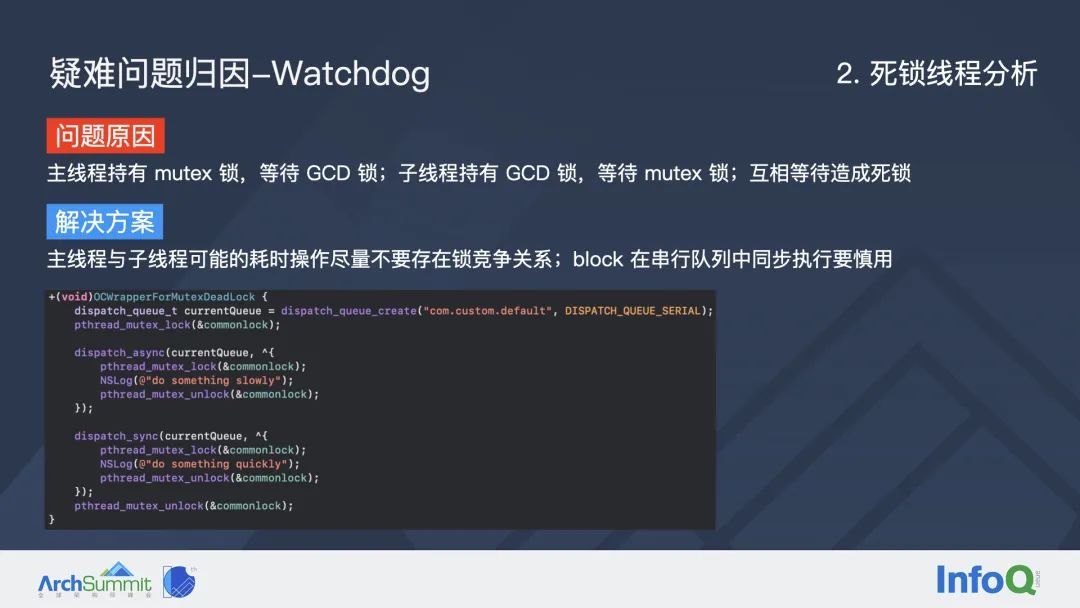
这是上图中死锁问题的一段示意的源码。它的问题就是主线程持有互斥锁,子线程持有 GCD 锁,两个线程之间互相等待造成了死锁。这里给出的解决方案是:如果子线程中可能存在耗时操作,尽量不要和主线程有锁竞争关系;另外如果在串行队列中同步执行 block 的话,一定要慎重。
上图是通过字节内部线上的监控和归因工具,总结出最常见触发卡死问题的原因,分别是死锁、锁竞争、主线程IO、跨进程通信。
OOM 就是 Out Of Memory,指的是应用占用的内存过高,最终被系统强杀导致的崩溃。
OOM 崩溃的危害有哪些呢?首先我们认为用户使用 App 的时间越长,就越容易发生 OOM 崩溃,所以说 OOM 崩溃对重度用户的体验伤害是比较大的;统计数据显示,如果 OOM 问题没有经过系统性的治理,它的量级一般是普通 Crash 的 3-5 倍。最后是内存问题不同于 Crash 和卡死,相对隐蔽,在快速迭代的过程中非常容易劣化。
那么 OOM 问题的归因难点有哪些呢?首先是内存的构成是非常复杂的事情,并没有非常明确的异常调用栈信息。另外我们在线下有一些排查内存问题的工具,比如 Xcode MemoryGraph 和 Instruments Allocations,但是这些线下工具并不适用于线上场景。同样是因为这个原因,如果开发者想在线下模拟和复现线上 OOM 问题是非常困难的。
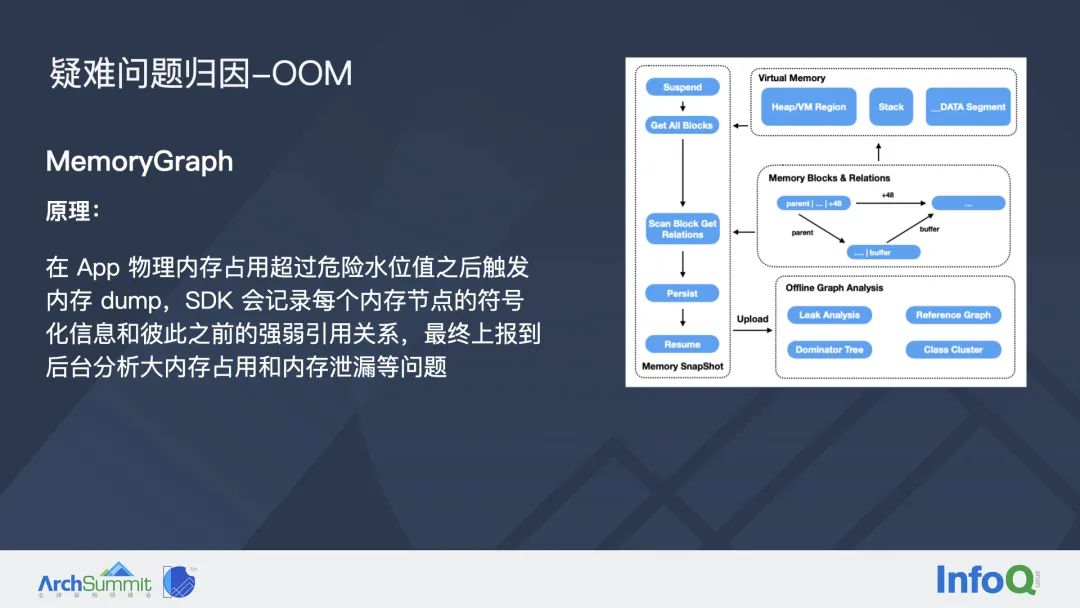
这里我们给出解决线上 OOM 疑难问题的归因工具是MemoryGraph。这里的 MemoryGraph 主要指的是在线上环境中可以使用的 MemoryGraph。跟 Xcode MemoryGraph 有一些类似,但是也有不小的区别。最大的区别当然是它能在线上环境中使用,其次它可以对分散的内存节点进行统计和聚合,方便开发者定位头部的内存占用。
这里带领大家再回顾一下线上 MemoryGraph 的基本原理:首先我们会定时的去检测 App 的物理内存占用,当它超过危险阈值的时候,就会触发内存 dump,此时 SDK 会记录每个内存节点符号化之后的信息,以及他们彼此之间的引用关系,如果能判定出是强引用还是弱引用,也会把这个强弱引用关系同时上报上来,最终这些信息整体上报到后台之后,就可以辅助开发者去分析当时的大内存占用和内存泄露等异常问题。
这里我们还是用一个实战案例带领大家看一下 MemoryGraph 到底是如何解决 OOM 问题的。
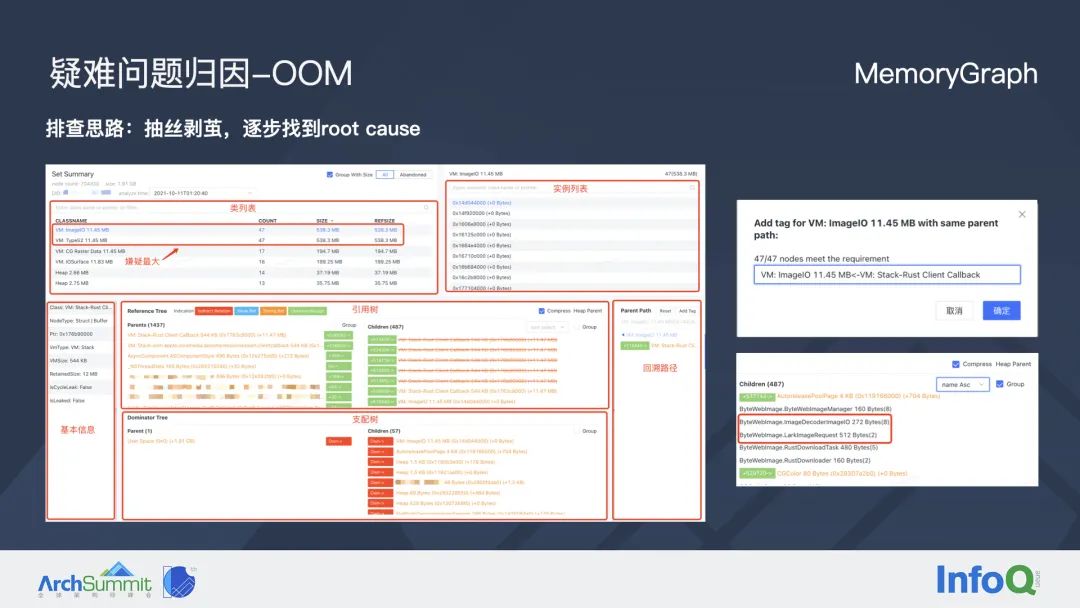
分析 MemoryGraph 文件的思路一般是抽丝剥茧,逐步找到根本原因。
上图是 MemoryGraph 文件分析的一个例子,这里的红框标注了不同的区域:左上角是类列表,会把同一类型对象的数量以及它们占用的内存大小做一个汇总;右侧是这个类所有实例的地址列表,右下角区域开发者可以手动回溯对象的引用关系(当前对象被哪些其他对象引用、它引用了哪些其他对象),中间比较宽的区域是引用关系图。
因为不方便播放视频,所以这边就跟大家分享一些比较关键的结论:首先看到类列表,我们不难发现 ImageIO 类型的对象有 47 个,但是这 47 个对象居然占了 500 多 MB 内存,显然这并不是一个合理的内存占用。我们点开 ImageIO 的类列表,以第一个对象为例,回溯它的引用关系。当时我们发现这个对象只有一个引用,就是 VM Stack: Rust Client Callback ,它实际上是飞书底层的 Rust 网络库线程。
排查到这里,大家肯定会好奇:这 47 个对象是不是都存在相同的引用关系呢?这里我们就可以用到右下角路径回溯当中的 add tag 功能,自动筛选这 47 个对象是否都存在相同的引用关系。大家可以看到上图中右上角区域,通过筛选之后,我们确认这 47 个对象 100% 都有相同的引用关系。
我们再去分析 VM Stack: Rust Client Callback这个对象。发现它引用的对象中有两个名字非常敏感,一个是 ImageRequest,另外一个是 ImageDecoder ,从这两个名字我们可以很容易地推断出:应该是图片请求和图片解码的对象。
我们再用这两个关键字到类列表中搜索,可以发现 ImageRequest 对象有 48 个,ImageDecoder 对象有 47 个。如果大家还有印象的话,上一页中占用内存最大的对象 ImageIO 也是 47 个。这显然并不是一个巧合,我们再去排查这两类对象的引用关系,发现这两类对象也同样是 100% 被 VM Stack: Rust Client Callback 对象所引用。
最终我们和飞书图片库的同学一起定位到这个问题的原因:在同一时刻并发请求 47 张图片并解码,这不是一个合理的设计。问题的根本原因是飞书图片库的下载器依赖了 NSOperationQueue 做任务管理和调度,但是却没有配置最大并发数,在极端场景下就有可能造成内存占用过高的问题。与之相对应的解决方案就是对图片下载器设置最大并发数,并且根据待加载图片是否在可视区域内调整优先级。
上图是通过字节内部的线上监控和归因工具,总结出来最常见的几类触发 OOM 问题的原因,分别是:内存泄露,这个较为常见;第二个是内存堆积,主要指的是 AutoreleasePool 没有及时清理;第三是资源异常,比如加载一张超大图或者一个超大的 PDF 文件;最后一个是内存使用不当,比如内存缓存没有设计淘汰清理的机制。
3.4 第四类疑难问题 —— CPU 异常和磁盘 I/O 异常
这里之所以把这两类问题合并在一起,是因为这两类问题是高度相似的:首先它们都属于资源的异常占用;另外它们也都不同于闪退,导致崩溃的原因并不是发生在一瞬间,而都是持续一段时间的资源异常占用。
异常 CPU 占用和磁盘 I/O 占用危害有哪些呢?首先我们认为,这两类问题即使最终没有导致 App 崩溃,也特别容易引发卡顿或者设备发烫等性能问题。其次这两类问题的量级也是不可以被忽视的。另外相比之前几类稳定性问题而言,开发者对这类问题比较陌生,重视程度不够,非常容易劣化。
这类问题的归因难点有哪些呢?首先是刚刚提到它的持续时间非常长,所以原因也可能并不是单一的;同样因为用户的使用环境和操作路径都比较复杂,开发者也很难在线下复现这类问题;另外如果 App 想在用户态去监控和归因这类问题的话,可能需要在一段时间内高频的采样调用栈信息,然而这种监控手段显然性能损耗是非常高的。
上图中左侧是我们从 iOS 设备中导出的一段 CPU 异常占用的崩溃日志,截取了关键部分。这部分信息的意思是:当前 App 在 3 分钟之内的 CPU 时间占用已经超过80%,也就是超过了 144 秒,最终触发了这次崩溃。
上图中右侧是我截取苹果 WWDC2020 一个 session 中的截图,苹果官方对于这类问题,给出了一些归因方案的建议:首先是 Xcode Organizer,它是苹果官方提供的问题监控后台。然后是建议开发者也可以接入 MetricKit ,新版本有关于 CPU 异常的诊断信息。
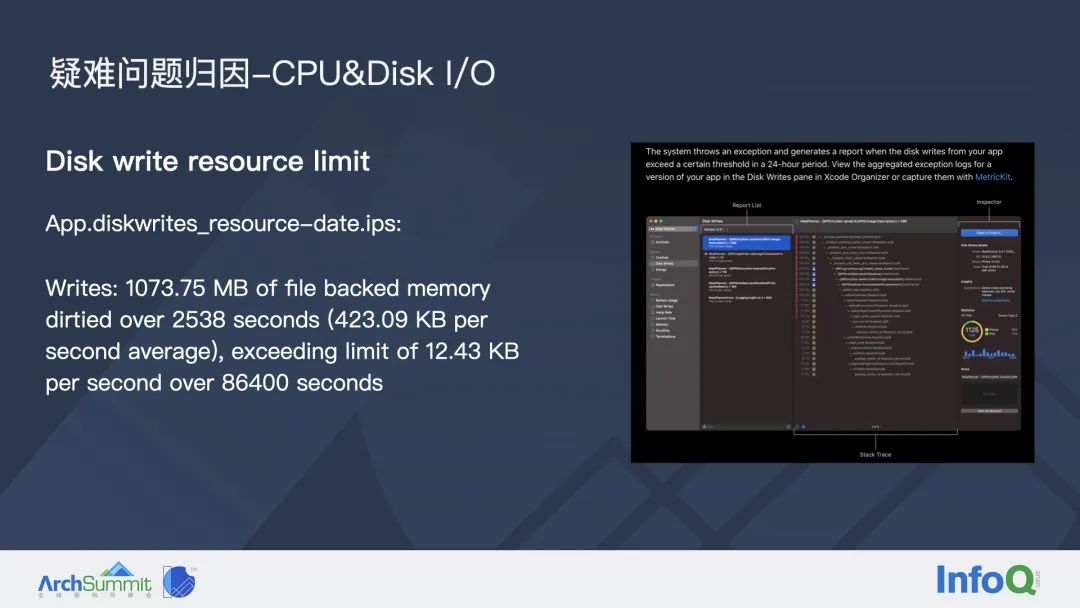
上图中左侧是磁盘异常写入的崩溃日志,也是从 iOS 设备中导出,依然只截取了关键部分:在 24 小时之内,App 的磁盘写入量已经超过了 1073 MB,最终触发了这次崩溃。
上图中右侧是苹果官方的文档,也给出了对于这类问题的归因建议。同样是两个建议:一个是依赖 Xcode Organizer,另一个是依赖 MetricKit。我们选型的时候最终确定采用 MetricKit 方案,主要考虑还是想把数据源掌握在自己手中。因为 Xcode Organizer 毕竟是一个苹果的黑盒后台,我们无法与集团内部的后台打通,更不方便建设报警、问题自动分配、issue状态管理等后续流程。
MetricKit 是苹果提供的官方性能分析以及稳定性问题诊断的框架,因为是系统库,所以它的性能损耗很小。在 iOS 14 系统以上,基于Metrickit,我们可以很方便地获取 CPU 和磁盘 I/O 异常的诊断信息。它的集成也非常方便。我们只需要导入系统库的头文件,设置一个监听者,在对应的回调中把 CPU 和磁盘写入异常的诊断信息上报到后台分析就好了。
其实这两类异常的诊断信息格式也是高度类似的,都是记录一段时间内所有方法的调用以及每个方法的耗时。上报到后台之后,我们可以把这些数据可视化为非常直观的火焰图。通过这样直观的形式,可以辅助开发者轻松地定位到问题。对于上图中右侧的火焰图,我们可以简单的理解为:矩形块越长,占用的 CPU 时间就越长。那么我们只需要找到矩形块最长的 App 调用栈,就能定位到问题。图中高亮的红框,其中有一个方法的关键字是 animateForNext,看这个名字大概能猜到这是动画在做调度。
最终我们和飞书的同学一起定位到这个问题的原因:飞书的小程序业务有一个动画在隐藏的时候并没有暂停播放,造成了 CPU 占用持续比较高。解决方案也非常简单,只要在动画隐藏的时候把它暂停掉就可以了。
四、总结回顾
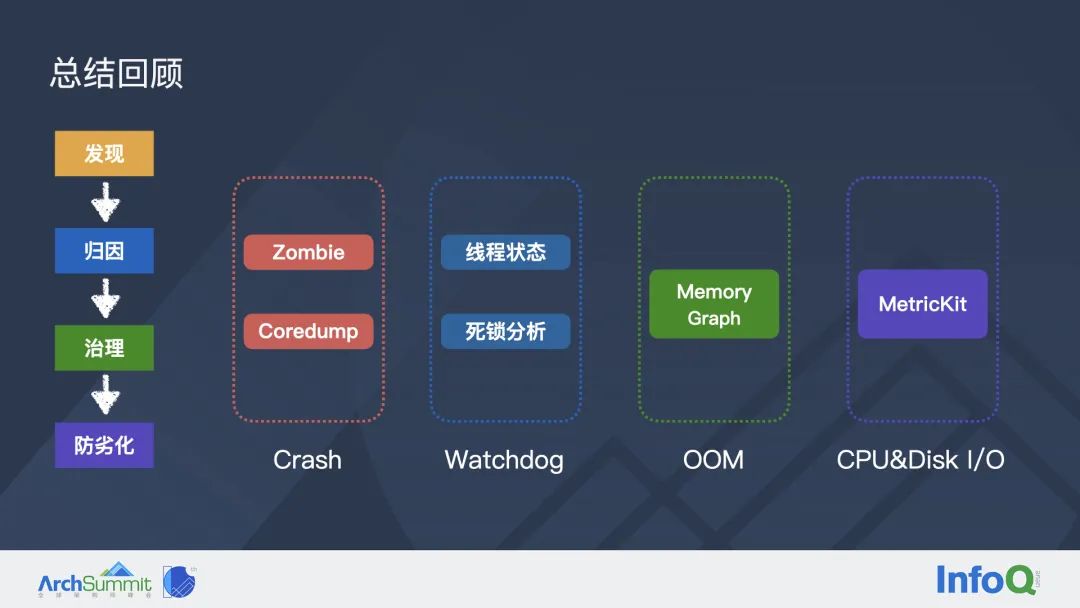
在第二章节稳定性问题治理方**中,我提到“如果想把稳定性问题治理好,就需要将这件事情贯穿到软件研发周期中的每一个环节,包括问题的发现、归因、治理以及防劣化。”同时我们认为线上问题——特别是线上疑难问题的归因,是整个链路中的重中之重。针对每一类疑难问题,本次分享均给出了一些好用的归因工具:Crash 有 Zombie 监控和 Coredump;Watchdog 有线程状态和死锁线程分析;OOM 有 MemoryGraph;CPU 和磁盘 I/O 异常有 MetricKit。
本次分享提到的所有疑难问题的归因方案,除了MetricKit 之外,其余均为字节跳动自行研发,开源社区尚未有完整解决方案。这些工具和平台后续都将通过字节火山引擎应用开发套件MARS下的 APM Plus 平台提供一站式的企业解决方案。本次分享提到的所有能力均已在字节内部各大产品中验证和打磨多年,其自身的稳定性以及接入后所带来的业务效果都是有目共睹的,欢迎大家持续保持关注。
火山引擎 APMPlus 应用性能监控是火山引擎应用开发套件 MARS 下的性能监控产品。我们通过先进的数据采集与监控技术,为企业提供全链路的应用性能监控服务,助力企业提升异常问题排查与解决的效率。
目前我们面向中小企业特别推出「APMPlus 应用性能监控企业助力行动」,为中小企业提供应用性能监控免费资源包。现在申请,有机会获得60天免费性能监控服务,最高可享6000万条事件量。

👆 扫码添加小助手