一、前言
如何定位和解决 Android App 因为内存不足(Java OOM)引发的线上问题一直是业界的难题。崩溃现场能抓取到的常规信息中并不包括内存分配详情——不了解内存被谁持有,自然也无法追查内存不足的根源。
针对这个问题,Client Infra 和头条抖音等业务方合作,通过一系列技术调研,自研了一套基于 Hprof 内存快照的线上 Java OOM 归因方案,在内部广泛应用并取得了极佳的效果。曾帮助Helo在一个双月内优化了80%的 Java OOM 问题,次日存留增长了2+%。
在火山引擎 MARS-APMPlus 应用性能监控平台对外提供该解决方案后,美篇作为早期接入客户,也同样取得了双月周期减少80% Java OOM的好成绩,深受客户好评。
接下来本文将会从 Java 内存基础开始,详细介绍方案的底层原理与技术细节。希望大家能通过方案了解MARS-APMPlus 应用性能监控平台,加入我们的MARS-APMPlus 应用性能监控企业助力行动,帮助团队打造极致的用户体验。
2.1 Java 内存优化的重要性
内存是计算机的稀缺资源,操作系统本身也通过虚拟内存等方式来充分的使用内存资源。
如果Java 堆内存占用过多,JVM 频繁GC会引起App的卡顿,影响App的易用性 。
更严重的Java 堆内存使用超过虚拟机限制会导致OOM崩溃,影响App的可用性 。
从App的易用性和可用性来说,Java 内存的优化还是十分重要的,特别是用户使用应用的崩溃问题,应该得到有效解决。
2.2 为什么会Java OOM崩溃
Java OOM,全称是Java Out Of Memory,字面意思是说Java 虚拟机的内存用完。Java有一个相关的异常类java.lang.OutOfMemoryError,官方有如下说明:
Thrown when the Java Virtual Machine cannot allocate an object because it is out of memory, and no more memory could be made available by the garbage collector.
就是说,当Java 虚拟机没有更多的内存可以为对象分配空间,垃圾回收器也没有更多的空间可以回收时,就会抛出这个Error。
这里面有几个关键点,理解这几个关键点,我们就会理解为什么会Java OOM崩溃
-
-
-
-
Java 虚拟机当前的内存空间状态以及OOM是如何发生的
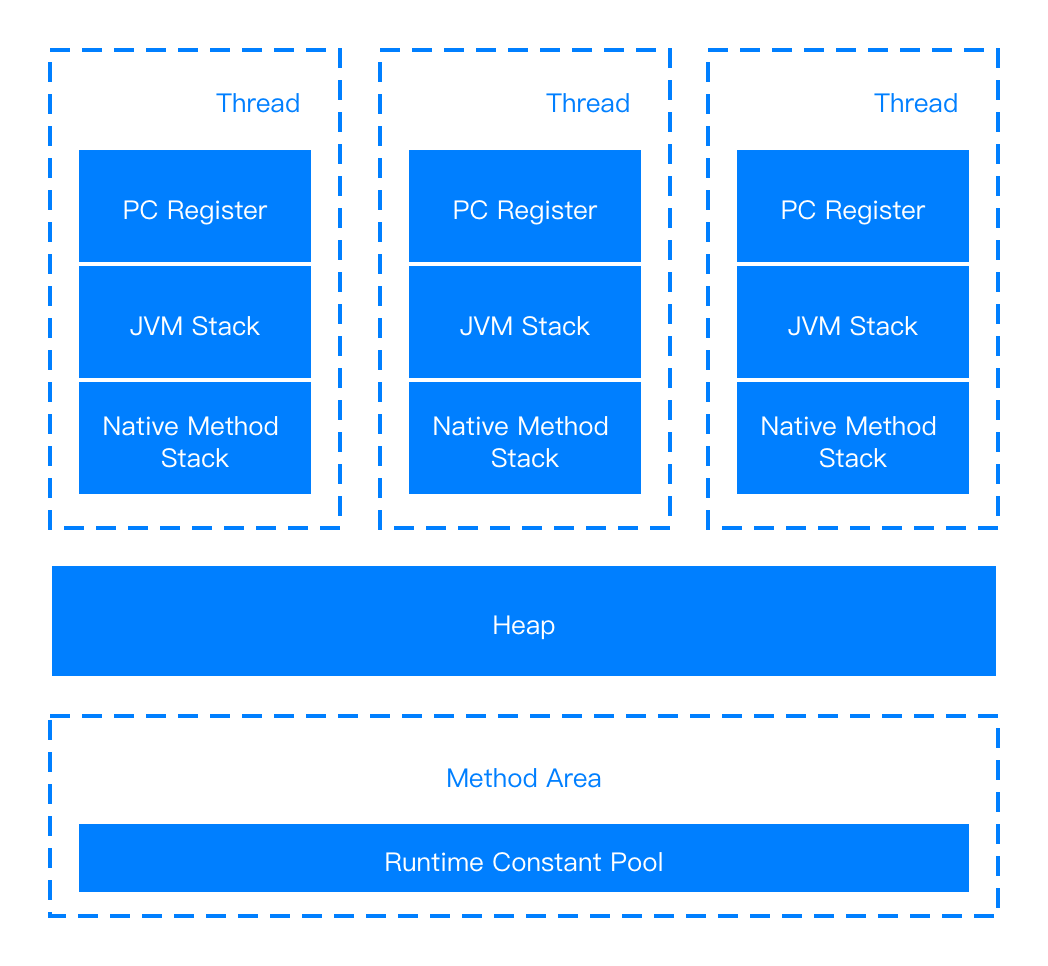
2.1.1 Java虚拟机的内存区域
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域,如下图所示:
下面是每个区域的一个概要说明:
| 名称 |
说明 |
|
PC Register
|
称为程序计数器, 看作是当前线程所执行的字节码的行号指示器
|
|
JVM Stack
|
也称为虚拟机栈,记录每个栈帧(Frame)中的局部变量、方法返回地址等
|
|
Native Method Stack
|
本地 (原生) 方法栈,是调用操作系统原生本地方法时,所需要的内存区域
|
|
Heap
|
堆内存区,也是 GC 垃圾回收的主要场所,用于存放类的实例对象
|
|
Method Area
|
方法区,主要存放类结构、类成员定义,static 静态成员等
|
|
Runtime Constant Pool
|
运行时常量池,比如:字符串等
|
其中我们需要重点关注的是线程间共享的Heep堆内存区域。这部分区域是GC垃圾回收的主要场所,用于存放类的实例对象。我们最常见的Java OOM都是因为堆内存使用超出虚拟机最大可用内存阈值导致的崩溃。垃圾回收机制也是针对堆内存部分。
2.1.2 垃圾回收器是如何工作回收内存的
Java 虚拟机有自动内存管理机制,通过垃圾回收器来管理内存,一旦确定程序不再使用某块内存,它就会将该内存回收。
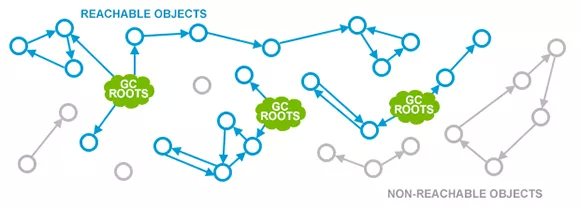
垃圾回收器当前主要通过可达性分析算法判断一个对象是否可以被回收:通过一系列称为GC Roots的对象作为起点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连(即对象到GC Roots不可达),则证明此对象已死、可回收。下图灰色部分即为可回收的内存对象。
GC Roots是可以从堆外部访问的对象,例如Java线程当前活跃的栈帧里指向GC堆里的对象的引用,就是当前正在被调用方法的引用类型的参数和局部变量等。
垃圾回收有不同的收集算法,和不同类型的垃圾收集器,这里只是概述背景不再详细说明。是否可回收的核心是判断一个对象是否到GC Roots不可达,不可达则对象会被回收释放内存空间。
这里我们知道了一个对象在什么情况下被回收的。如果在内存里没有被回收,那就是因为有GC Root对它持有引用。在内存充足并有足够大的连续空间时,虚拟机会创建对象正常分配内存。
2.1.3 对象占据多大的内存空间
上面我们知道了一个对象是如何被回收的,那么内存中的对象到底占据多大的内存呢。这里会先介绍一个概念 Dominator Tree 支配树,Dominator Tree有以下几个定义:
-
对象X
Dominator Tree(支配)对象Y,当且仅当在对象树中所有到达Y的路径都必须经过 X
-
对象Y的直接
Dominator Tree,是指在对象引用关系中距离Y最近的Dominator
-
Dominator Tree利用对象引用关系构建出来
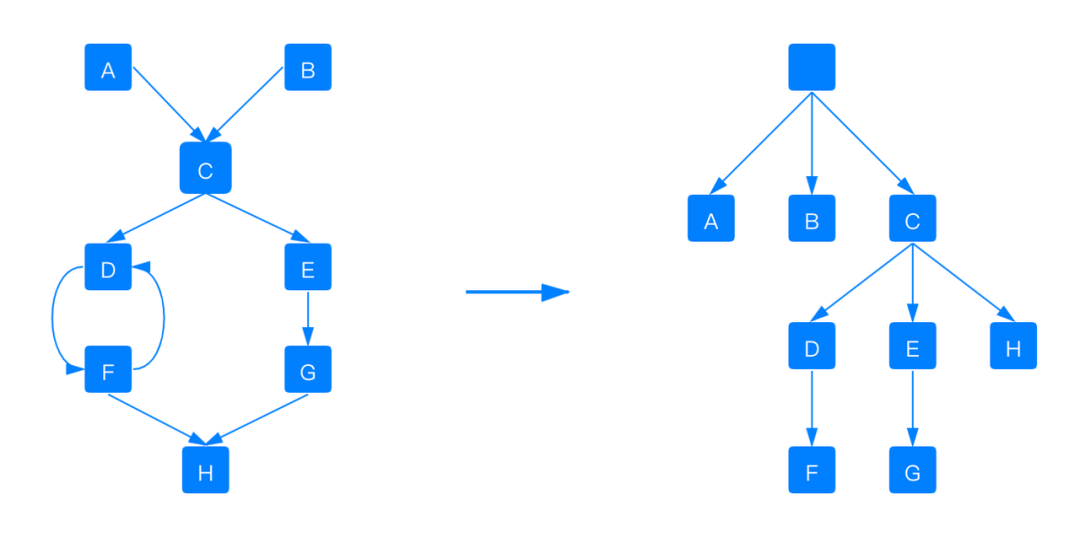
对象引用关系和Dominator Tree的对应关系如下:
如上图,因为A和B都引用到C,所以A释放时,C内存不会被释放。所以C这块内存不会被计算到A或者B的Retained Size中,因此,对象树在转换成Dominator Tree时,会A、B、C三个是平级的。
将对象引用关系转换成Dominator Tree能帮助我们快速的发现占用内存最大的块,也能帮我们分析对象之间的依赖关系。
根据支配关系,对象大小有两个定义Retained Size和Shallow Size:
-
Shallow Size : 对象本身占用内存的大小。也就是对象头加成员变量(不是成员变量的值)的总和,如一个引用占用32或64bit,一个integer占4bytes,Long占8bytes等。常规对象(非数组)的Shallow Size 由其成员变量的数量和类型决定,数组的 Shallow Size 由数组元素的类型(对象类型、基本类型)和数组长度决定。例如E的Shallow Size,只是自身大小和他引用的G没有关系。
-
Retained Size : 对象被垃圾回收器回收后能被GC从内存中移除的所有对象内存大小之和。相对于Shallow Size,Retained Size可以更精确的反映一个对象实际占用的大小(若该对象释放,Retained Size都可以被释放)。例如E到C的引用链断开后,会释放E、G这2个对象。这2个对象的所占内存之和就是E的Retained Size。
这里我们就知道了如果要优化内存或者解决泄露,优先关注 Retained Size 较大的对象,因为Retained Size大的对象所能释放的内存空间更大。
2.1.4 Java OOM的发生
学习了内存区域,垃圾回收机制,以及对象所占用的内存空间大小,那么Java OOM 到底是如何发生的呢。下面我们来看一个Java OOM异常时候的信息:
java.lang.OutOfMemoryError: Failed to allocate a 65552 byte allocation with 23992 free bytes and 23KB until OOM, max allowed footprint 536870912, growth limit 536870912
OutOfMemoryError 抛出的地方在系统源码文件/runtime/gc/heap.cc
//方法
void Heap::ThrowOutOfMemoryError(Thread* self, size_t byte_count, AllocatorType allocator_type)
//异常信息
oss << "Failed to allocate a " << byte_count << " byte allocation with " << total_bytes_free
<< " free bytes and " << PrettySize(GetFreeMemoryUntilOOME()) << " until OOM,"
<< " target footprint " << target_footprint_.load(std::memory_order_relaxed)
<< ", growth limit "
<< growth_limit_;
看上面异常日志,Java 虚拟机堆内存只剩下23992字节,无法分配65552字节的空间,抛出OutOfMemoryError 异常。
-
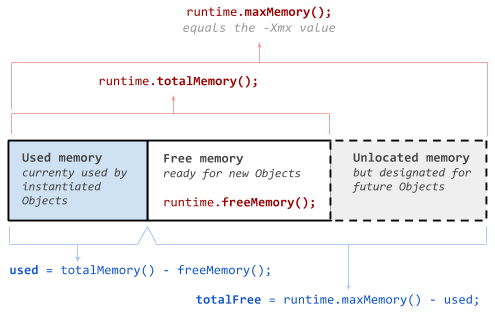
Android可以通过如下接口获取到当前虚拟机的内存状态。
-
Runtime.getRuntime().maxMemory() :当前虚拟机实例的内存使用上限
-
Runtime.getRuntime().totalMemory() :当前已经申请的内存,包括已经使用的和还没有使用的
-
Runtime.getRuntime().freeMemory() :totalMemory中已经申请但是尚未使用的部分
-
used=totalMemory() - freeMemory():已经申请并且正在使用的部分
-
totalFree=maxMemory()-used:Java虚拟机还可以使用的部分
如果可用的内存无法提供分配对象所需的空间,则会产生 OutOfMemoryError 异常。
本文主要讲解最常遇到的Java 堆内存用尽导致的OOM问题解决方案。由于线程数据超限,虚拟内存用尽导致的OOM并不在当前的解决方案内。
2.3 Java内存相关工具
针对Java 堆内存问题,当前业界已经提供了一些分析Java内存的工具,内部也做了一些接入和测试
| 工具名称 |
介绍 |
优点 |
缺点 |
|
|
The Eclipse Memory Analyzer is a fast and feature-rich that helps you find memory leaks and reduce memory consumption.
|
分析功能强大
|
线下分析,需要自己采集Hprof文件
|
|
LeakCanary
|
LeakCanary is a memory leak detection library for Android.
|
可以接入App自动分析
|
线下分析,主要分析内存泄露
|
|
Android Studio Memory Profiler
|
可帮助用户识别可能会导致应用卡顿、冻结甚至崩溃的内存泄露和内存抖动
|
可以动态内存监控,也可以静态内存分析
|
线下分析,需要App debug模式
|
经过测试这些工具很难满足产品解决Java OOM的需求,主要存在以下问题:
-
-
-
都是单点工具,只能分析单个hprof文件,没法聚合找到核心问题
由于业界已有工具无法满足解决线上Java OOM问题的需要,内部调研开发了一套基于Hprof内存文件的线上Java OOM归因方案,解决已有工具的痛点,可以高效解决线上Java OOM问题。工具拥有以下特点:
-
高度还原现场: 可以拿到Java OOM时候的现场内存数据
-
-
聚合找到核心问题: 可以根据问题特征聚合发现核心问题
-
隐私安全: 因为是线上监控,所以需要满足用户隐私安全的要求
因为方案是根据Hprof内存文件进行设计,在进行详细方案讲解之前,先介绍一下Hprof内存文件。
3.1 Hprof基础知识
3.1.1 Hprof介绍
Hprof最初是由J2SE支持的一种二进制堆转储格式,Hprof文件保存了当前java堆上所有的内存使用信息(包括但不限于Class类信息、对象信息、引用关系等等),能够完整的反映虚拟机当前的内存状态。
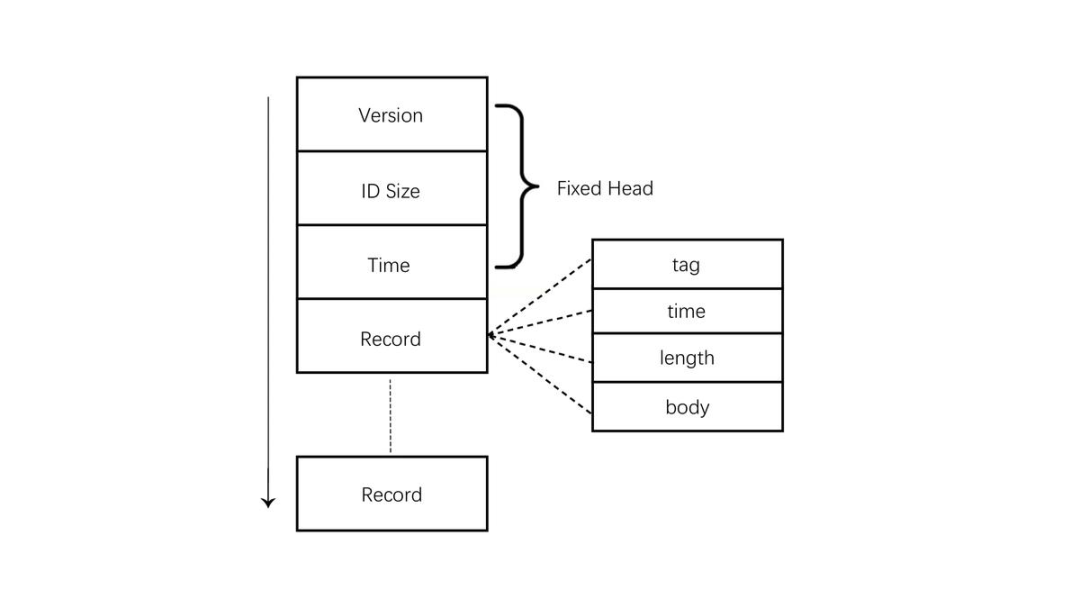
Hprof文件由Fixed Head和一系列的Record组成,Record包含字符串信息、类信息、栈信息、GC Root信息、对象信息。每个Record都是由1个字节的Tag、4个字节的Time、4个字节的Length和Body组成,Tag表示该Record的类型,Body部分为该Record的内容,长度为Length。
3.1.3 Hprof文件使用
Android Studio Memory Profiler、 LeakCanary、MAT 等工具分析内存信息和引用链都是依赖Hprof文件。
Android可以dump获取到Hprof内存文件,我们当前的方案也是基于获取到的Hprof文件来分析内存问题进行归因。
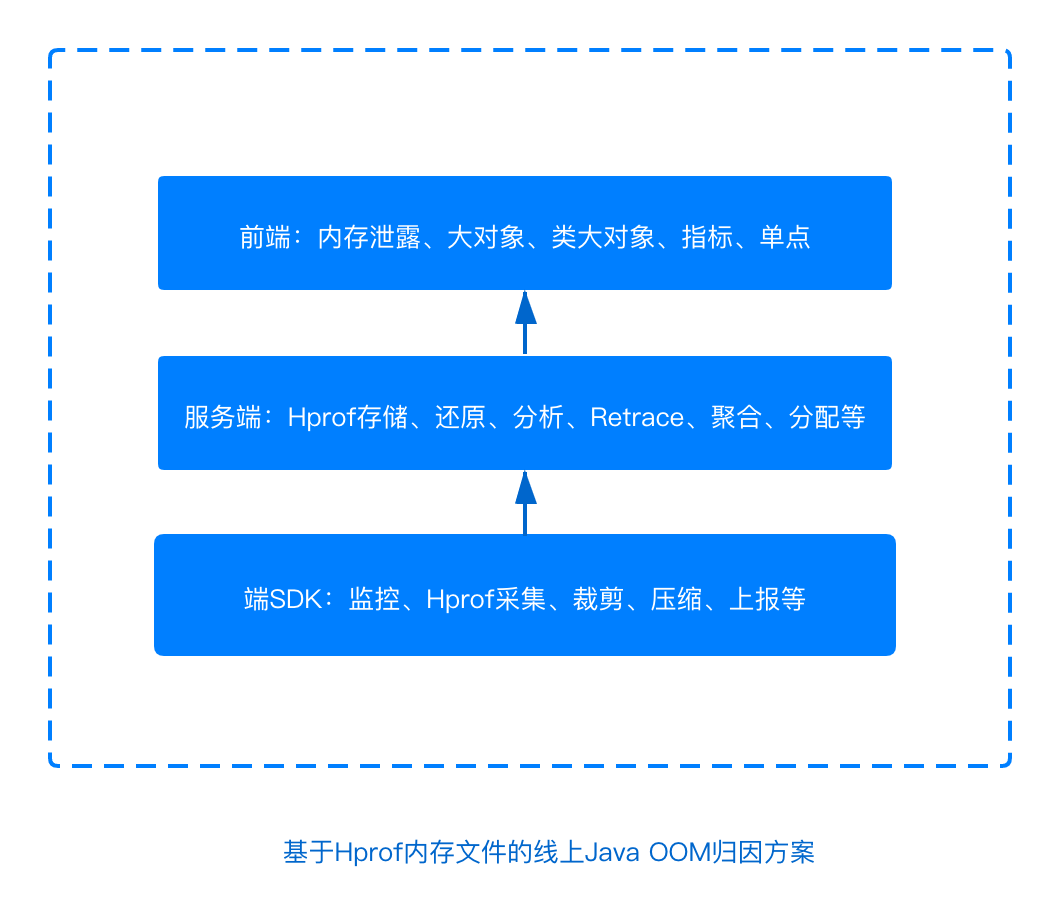
3.2 方案概要
1. 端 SDK :负责Hprof文件的采集、裁剪、压缩及上报等
2. 服务端:Hprof 文件存储、 还原、自动 分析、结果Retrace、issue聚合,自动分配等
3. 前端 :问题展示包括内存泄露、大对象、 类大对象等
这个图比较清晰的介绍了方案的整个流程,业务方只需要接入SDK,就可以在平台查看核心内存问题,其他都是无感知的。
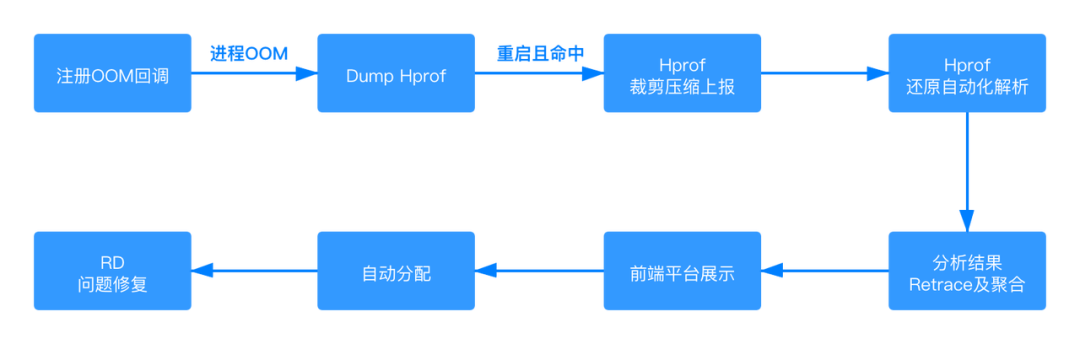
3.3 方案原理
3.2.1 内存文件端上dump
SDK默认是在Java OOM 时dump内存快照端SDK会注册主进程的 UncaughtExceptionHandler,同时判断是 Java OOM异常 ,然后会进行内存快照的 dump 操作。
Android中可以通过Debug.dumpHprofData()获取到一个Hprof文件,也支持使用Tailor通过xHook在 native 层 hook dump 同时裁剪的方式。
-
OOM之后还要再进行 dump 操作确实会容易dump失败。
-
OOM时候App崩溃不可用,dump操作会在崩溃时候导致卡顿。
通过fork系统调用创建子进程,这样子进程就有父进程的拷贝,我们把耗时的dump操作在子进程做就可以了。这样就提高了dump的成功率,也对App用户交互无感知。当前也支持在平台配置内存触顶子进程dump的模式。内存触顶是指当前内存使用占最大内存的比例,默认是80%,支持配置。
当前默认依然使用Java OOM时候dump,因为这时更能还原内存严重不当使用的真实现场。
3.2.2 内存文件的裁剪和还原
-
规避隐私风险:Hprof保存了执行Dump时刻Java堆上所有的内存信息,包括存在内存中的账户信息等,这些敏感信息必须裁剪掉。
-
减小文件大小:因为堆内存不足而OOM的时候获到的Hprof文件,约等于设备单进程最大可用内存,一般文件比较大有几百M,大文件上传浪费用户流量、带宽以及导致上报成功率降低。
分析解决 Java OOM 问题,我们主要关心对象的大小,以及它的引用链。对于Hprof里面的更多信息,例如图片像素数据,具体的字符串内容等我们并不关注,而且属于隐私数据,这部分数据是我们可以裁剪的。
1. 根据 Hprof 文件的格式进行分析,分析我们不需要关注的数据块
2. 将文件映射进内存,根据文件格式找到想要裁剪的数据块
实际裁剪掉的数据主要包括 String 的数组以及 Bitmap 对应的 mBuffer 数组(像素信息),这两部分涉及敏感信息且占据空间较大。其他更多裁剪内容不再详细说明。
上报到服务器的裁剪后Hprof文件,根据我们已知的裁剪方式,对裁剪的内容进行空字符填充还原。还原后的Hprof文件格式和裁剪之前相同。并不影响MAT等工具进行内存分析。
Hprof 文件大小变化明显: 头条裁剪前后数据平均值对比 355M -> 44M
3.2.3 内存文件的自动化解析
当服务端接收到上报的内存快照之后会进行自动的分析,直接定位内存核心问题,分析之后的结果主要包含三部分:
分析 Hprof 文件需要首先将 Hprof 文件按照格式进行解析, 并根据解析后数据构建引用关系图 。
我们参考业界已经存在的Hprof解析实现,包括MAT,LeakCanary等,实现了一套Hprof内存快照自动解析库。
下面讲解这三部分内容是如何定义的,如何解析的,解析了哪些数据用来归因,平台效果如何。
3.2.3.1 内存泄露
内存泄露是在计算机中,由于疏忽或错误造成程序未能释放已经不再使用的内存,是需要修复的问题。
例如Activity生命周期已经结束,执行了onDestroy(),但是依然存在到GC Root的引用链,导致Activity无法被GC回收。这个Activity 就可以认定为内存泄露。
根据Retained Size大小我们可以判断 Activity的泄露问题严重程度 ,越大越应该被优先解决。
根据GC引用链我们可以判断这个Activity泄露的原因,被谁持有导致的泄露,确认如何解决。
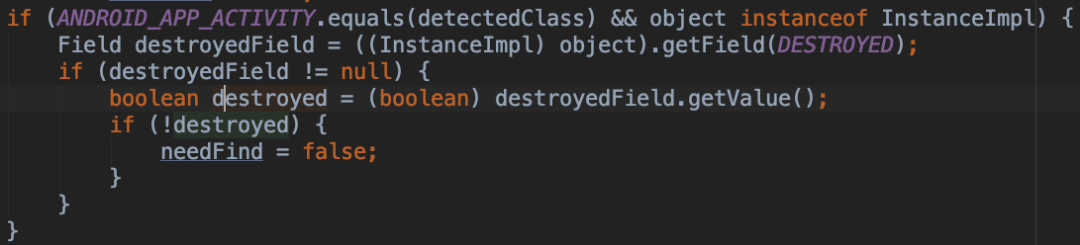
通过分析 Activity 的源码发现Activity调用 onDestroy 之后一个变量的值会发生变化,通过这个变量我们可以判断 Activity 是不是走了 onDestroy,如果走了那说明这个 Activity 对象存在属于泄露,没有走则说明属于正常使用。
private boolean mDestroyed;
final void performDestroy() {
mDestroyed = true;
xxx
}
通过Hprof解析库找出Activity的实例,并对其mDestroyed属性进行判断是否为true。这样就找到了泄露的Activity。
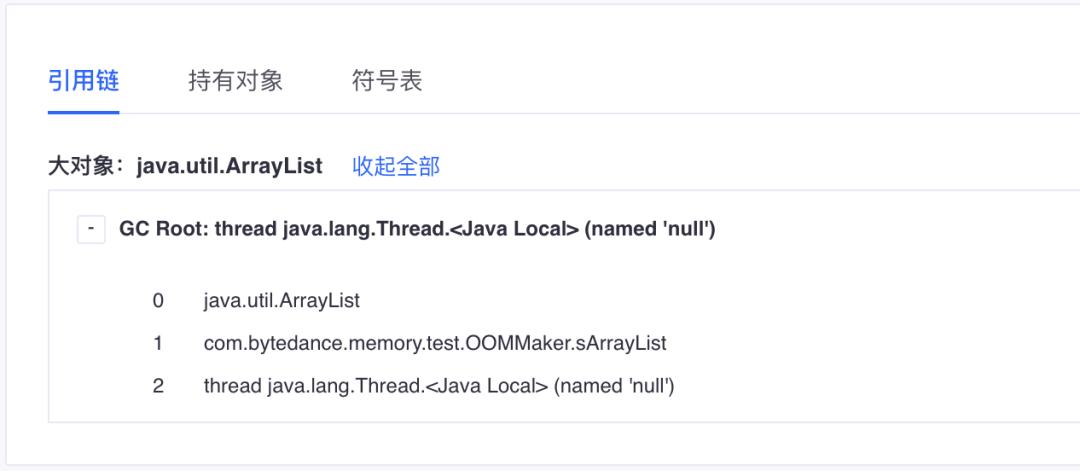
找到了泄露对象之后我们需要知道它究竟是被谁引用导致不能释放,上文已经介绍 Java 的垃圾回收机制通过可达性分析算法判断对象是否存活,一个对象能不能被回收就看 GC Root 到它之间有没有强引用链。泄露的对象和 GCRoot 之间必然是存在强引用链。
根据Hprof中的实例信息解析成描述引用关系的图结构后,使用经典的图搜索算法即可找到泄漏的对象到 GCRoot 的强引用链了,同时计算出对象的Retained Size大小。
泄露类 和导致它泄露的引用链非常直观展现了出来,可以通过断掉引用链来解决泄露。
所有发现的泄漏问题都应该被解决修复,上面的case是因为静态变量持有了Activity导致,这里的mContext可以通过替换为Application来解决。
3.2.3.2 大对象
大对象:顾名思义就是比较大的对象,前面背景知识里说的 RetainSize 较大的对象,也就是释放掉之后总共可以回收的较大的对象。
大对象标准:目前判断的依据是 RetainSize 大于 1 M 的对象会被当做大对象,然后去找引用链。
if (object != null && object.getRetainedHeapSize() > MINIMAL){
// 算作大对象
}
同时我们会计算大对象持有了谁导致他比较大,也是通过大对象持有的变量来计算判断。
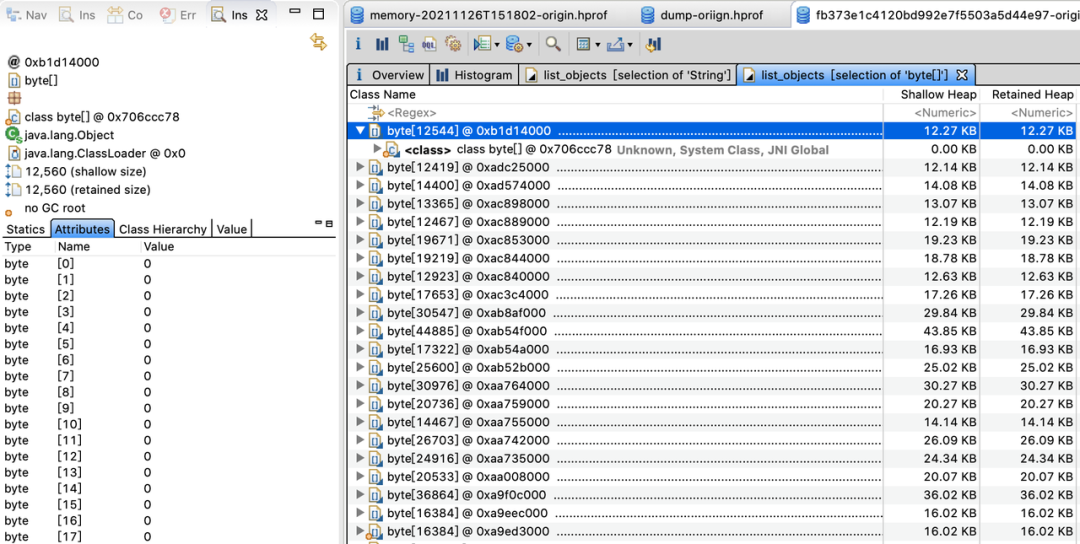
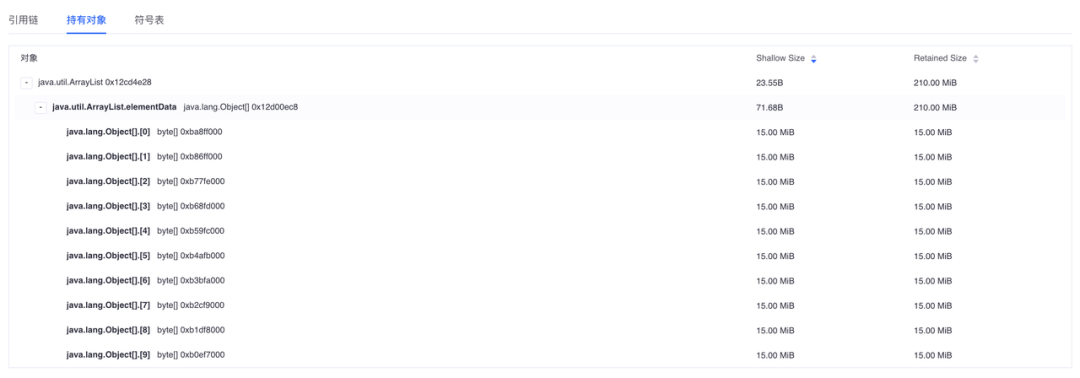
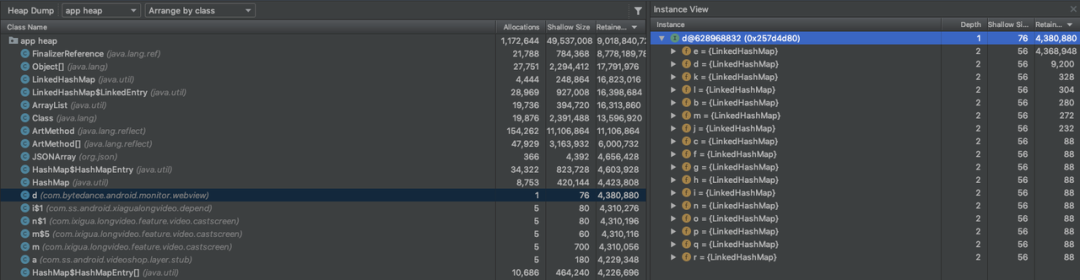
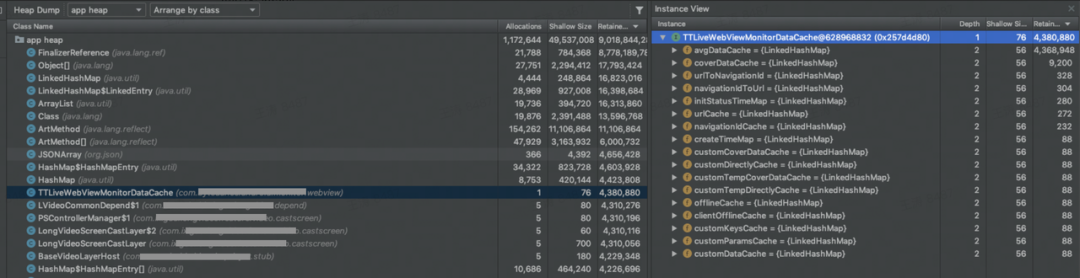
根据引用链判断这个大对象被谁持有引用,是否属于泄露可以修复。如果属于正常使用,判断大对象持有对象有谁,是否缓存过大可以清除部分缓存。下图可以看到内存缓存过大,Retained Size达到210M可以清除部分缓存优化。
大对象往往是导致Java OOM的核心问题,关注高频出现的Retained Size超大的大对象,优化后对Java OOM有非常好的优化效果。
3.2.3.3 类大对象
一个对象虽然比较小,但是它特别多,对象加在一起比较大也是需要我们重点关注的。例如一个对象只占10kb,但是如果内存里有2000个对象实例,总的内存占用也是特别大的。
当前类大对象的默认定义:对象实例数量超过10,Retained Size超过20M的类。
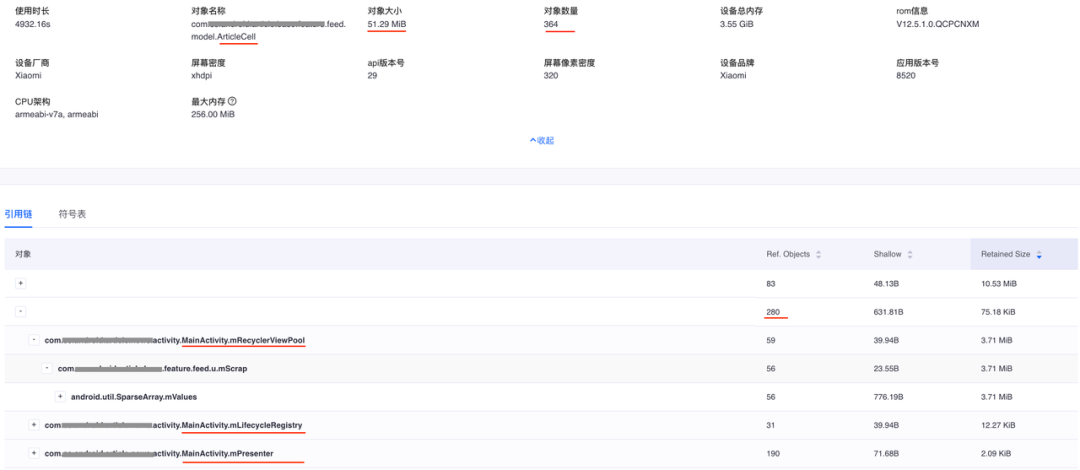
我们会解析出这部分类大对象,然后计算出他们的引用链。
上面的case是说类ArticleCell的对象有364个,总Retained Size 是51.29M。其中280个被MainActivity所持有。所以如果要优化ArticleCell的内存占用,可以优化MainActivity里面的引用。
3.2.4 聚合和Retrace
3.2.4.1 聚合
通过聚合我们可以找到同类问题,并把高频问题体现出来优先解决,达到四两拨千斤的效果。
泄露是通过泄露类和引用它的业务代码作为聚合特征来进行聚合。
大对象是通过大对象类和引用它的业务代码作为聚合特征来进行聚合。
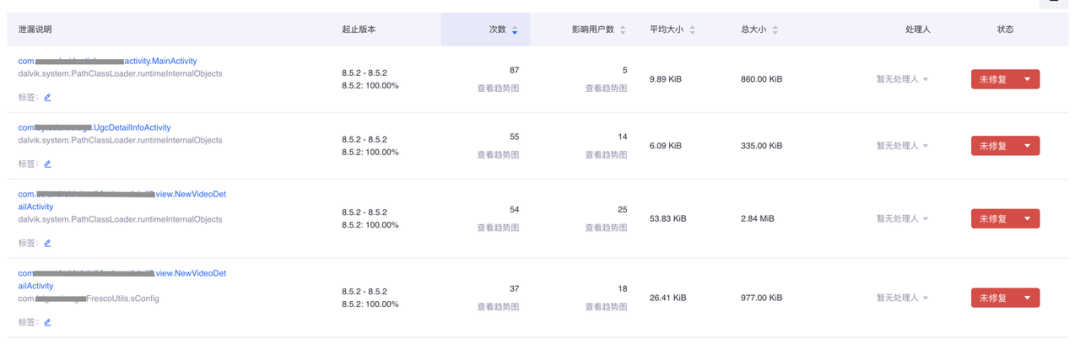
泄露的聚合效果如下,可以根据排序直接定位到高频泄露的Acitvity。
Hprof文件是混淆后的数据,对于解析出来的类名和引用链可以和崩溃一样通过符号表进行自动解析还原。
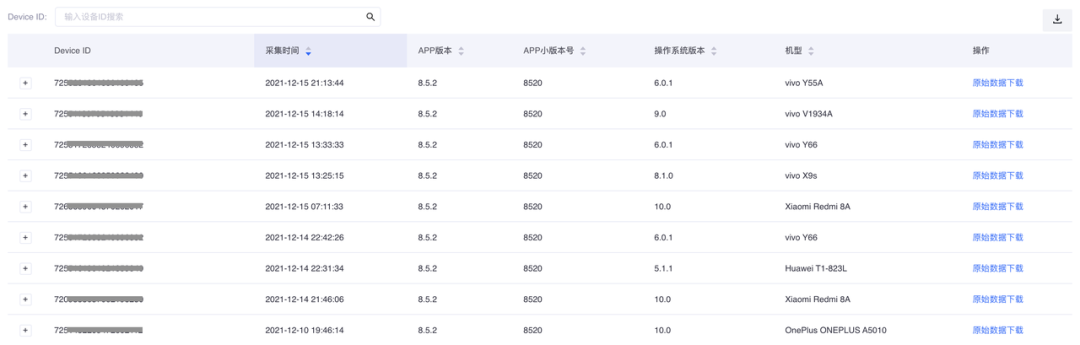
为了更好的分析单点问题,平台也提供了单点自动化分析数据展示和单点原始Hprof文件下载的能力。
对于下载下来的Hprof原始文件也是混淆后的,客户端分析非常不友好,是否可以把Hprof文件也进行反混淆还原呢。
当然可以,当前开发了一个Hprof文件Retrace工具,可以解析Hprof文件,读取类、变量和方法等数据,根据符号表还原成Retrace后的Hprof文件,线下分析更方便。
通过平台下载下来的Hprof就是经过填充还原Hprof结构,并且自动Retrace后的Hprof文件。
对于分析出来的问题,只分析出来还不足够,并没有实现闭环,我们需要通知到相应的同学去解决才可以,否则需要有同学来手动分配线上问题,比较浪费精力。
因此需要有自动分配的能力,内部通过解析聚合后issue的泄露Class,去代码仓库或者根据配置找这个 Class 的Owner,发送 Lark 通知给这位同学。
当前在火山引擎的MARS-APMPlus 应用性能监控无法获取用户的仓库解析Class Owner,暂时无法自动分配。
3.2.6 总结
以上就是这套基于Hprof内存快照的线上 Java OOM 归因方案的原理介绍,这套方案实现了高度现场还原、自动化内存分析、自动聚合Retrace、并实现了隐私安全。
接入后优先分析解决聚合后的TOP问题,包括频繁的泄露和频繁出现的大对象,对Java OOM指标会有非常明显的优化效果。
四、优化效果
4.1 内部效果
当前该解决方案已在字节内部广泛应用。包括头条抖音在内的数十个App业务方在接入后,Java OOM均有明显优化。以Helo为例,一个双月内优化了80+%的Java OOM问题,次日存留增长了2+%,效果显著。
当前这套方案已经在火山引擎 MARS-APMPlus 应用性能监控上线,美篇作为早期客户,在一个双月的优化后Java OOM 降低了80% ,用户卡顿率也下降了80% ,优化效果非常明显。
「MARS-APMPlus 应用性能监控企业助力行动」:MARS-APMPlus 应用性能监控 当前开始了企业助力行动,可以免费试用,欢迎注册试用产品,发现并解决Java OOM问题。MARS-APMPlus 应用性能监控除了支持对App进行监控,也支持对SDK进行稳定性监控和自定义事件打点。
进群:扫码进群,会有同学帮助开通 MARS-APMPlus 应用性能监控免费资源包。

MARS-APMPlus 应用性能监控 为企业提供 针对应用的品质、性能以及自定义埋点的 APMPlus 应用性能监控服务,帮助团队打造极致的用户体验。 基于海量数据的聚合分析,平台可帮助客户发现多类异常问题,并及时报警,做分配处理,同时平台提供了丰富的归因能力,包括且不限于异常分析、**分析、自定义上报、单点日志查询等,结合灵活的报表能力可了解各类指标的趋势变化。 APMPlus 应用性能监控已服务了抖音、今日头条、TikTok 等多个超大规模用户量级移动 App。
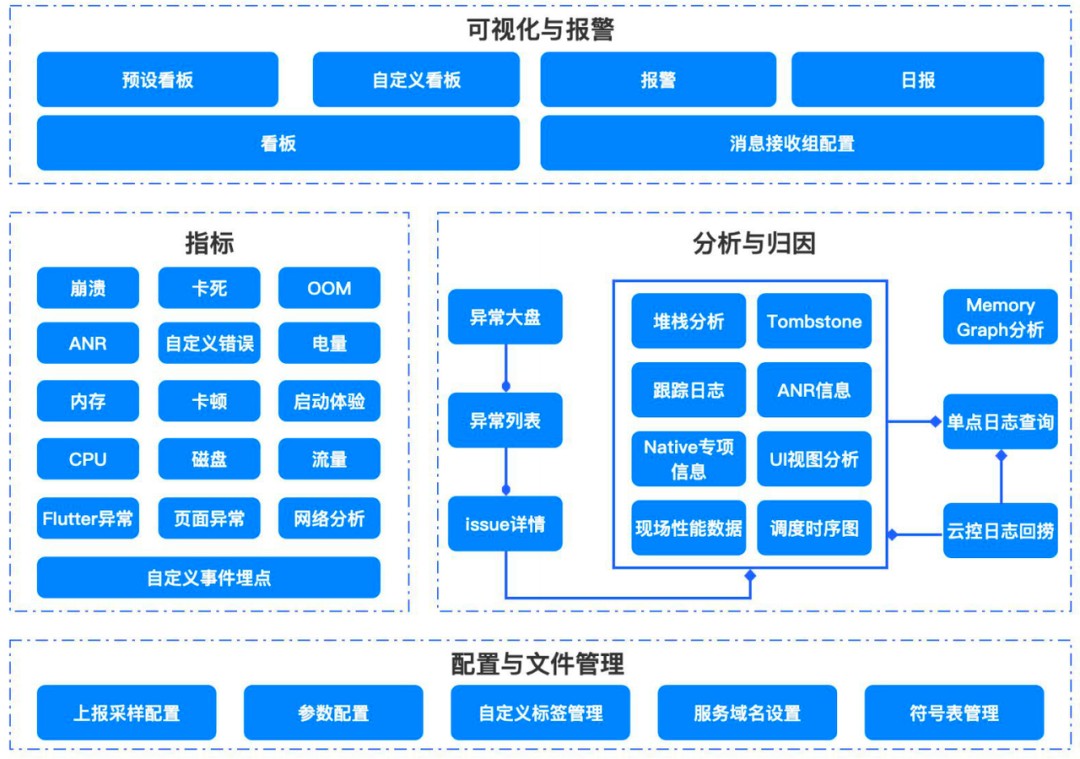
当前讲解的Java OOM解决方案,只是MARS-APMPlus 应用性能监控的一个功能模块,还有更多的能力会在后续进一步讲解,也欢迎同学抢先接入试用。
🔥 火山引擎 APMPlus 应用性能监控是火山引擎应用开发套件 MARS 下的性能监控产品。 我们通过先进的数据采集与监控技术,为企业提供全链路的应用性能监控服务,助力企业提升异常问题排查与解决的效率。
目前我们面向中小企业特别推出 「APMPlus 应用性能监控企业助力行动」 ,为中小企业提供应用性能监控免费资源包。 现在申请,有机会获得 60天 免费性能监控服务,最高可享 6000万 条事件量。