
生产故障|Kafka消息发送延迟达到几十秒的罪魁祸首竟然是...原创
以前我在知其然而知其所以然,为什么Kafka在2.8版本中会“抛弃”Zookeeper一文中阐述了为什么官方要废弃Zookeeper,当时我记得有读者反驳说zookeeper非常稳定,基本不会出现什么问题,笔者在双十一期间遇到的问题,就证明了Zookeeper的“脆弱性”,而zookeeper的脆弱性将对Kafka集群造成严重的影响。
1、故障现象
笔者在双十一期间负责的kafka集群的响应时间飙升到了10~30s,严重影响消息的写入。
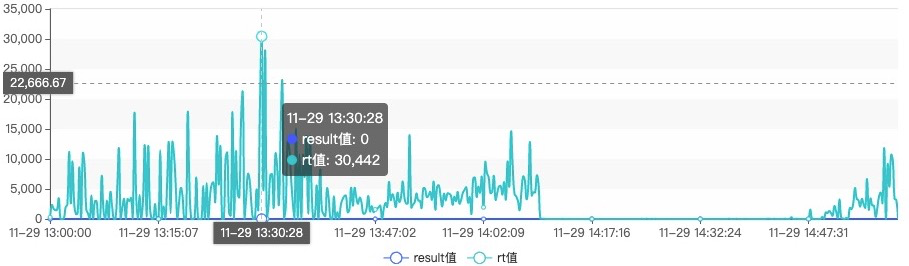
通过对日志分析发现存在大面积分区Leader选举,__consumer_offsets主题的分区也大量进行分区Leader选举,从而导致消息发送几乎停止,大量消费组触发重平衡,整个集群接近瘫痪,最终确定了根因:Broker节点与Zookeeper会话超时,触发大量分区重新选举。
本文借此故障,与大家一起剖析一下Zookeeper在Kafka中起了哪些作用,以及确定“罪魁祸首”的过程,希望给大家排查问题能带来一定的启发。
2、Zookeeper在Kafka中具有举足轻重的作用
在正式进入故障分析之前,我们首先介绍一下Zookeeper在kafka架构设计中所起的角色。
核心理念:kafka的设计者对待Zookeeper的使用是非常谨慎的,即需要依靠Zookeeper进行控制器选举,Broker节点故障实时发现,但又尽量降低对Zookeeper的依赖。
基于Zookeeper进行的程序开发,我们一般可以通过查看zookeeper中的目录布局,可以窥探出哪些功能是依靠Zookeeper完成,Kafka在Zookeeper中的存储目录结构如下图所示:
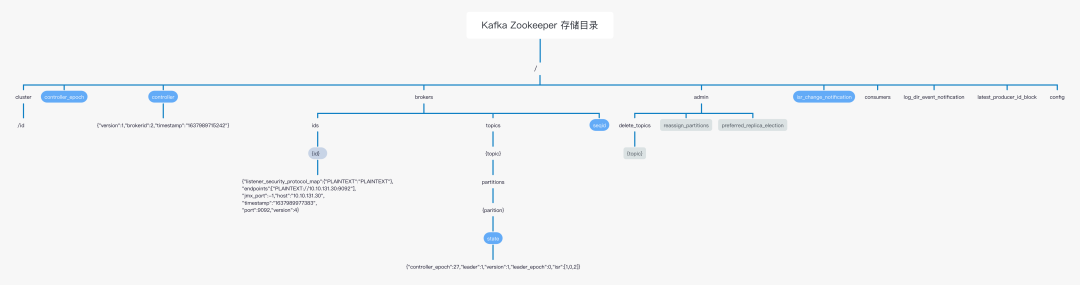
上述各个节点,其背后都关联着Kafka一个核心工作机制,大家可以顺藤摸瓜进行探究,本文需要重点介绍/brokers这个目录的布局与作用,目录详情如下:
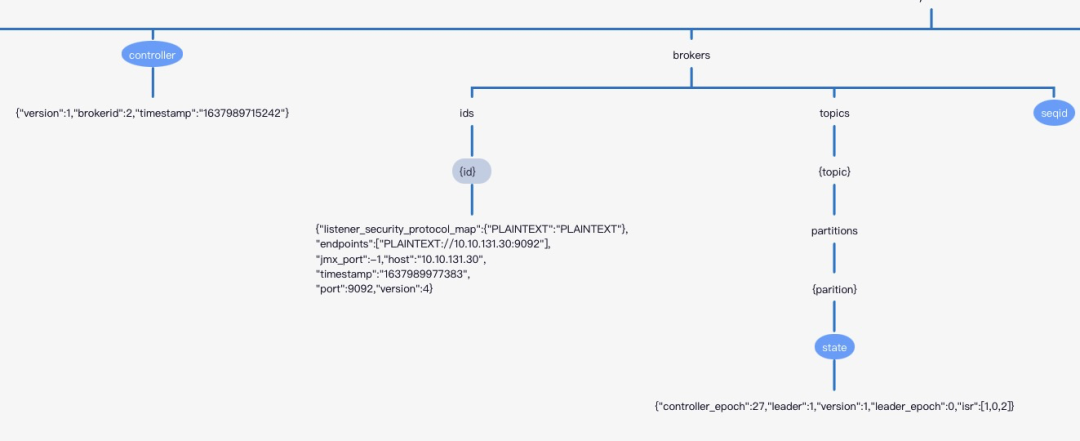
-
/controller Kafka控制器的信息,Kafka控制器的选举依靠zookeeper。
-
/brokers/ids/{id} 在持久节点/brokers/ids下创建众多的临时节点,每一个节点,表示一个Broker节点,节点的内容存储了Broker的基本信息,例如端口、版本、监听地址等。
-
/brokers/topics/{topic}/partitions/{partition}/state
在kafka2.8版本一下,Kafka中topic中的路由信息最终持久化在zookeeper中,每一个broker节点启动后会在内存中缓存一份数据。/brokers节点每一个子节点表示一个具体的主题,主题的元数据主要包括分区的个数与每一个分区的状态信息。每一个分区的状态信息主要包括:
-
controller_epoch 当前集群控制器的epoch,表示controller选举的次数,我们可以理解为controller的“版本号”。 -
leader 当前分区Leader所在的broker id。 -
Leader_epoch 分区的leader_epoch,表示分区Leader选举的次数,从0开始,每发生一次分区leader选举该值就会加一,kafka通过引入leader epoch机制解决低版本依靠依赖水位线表示副本进度可能造成的数据丢失与数据不一致问题,这个将在后续文章中深入剖析。 -
isr 分区的isr集合。 -
version 存储状态分区状态数据结构的版本号,这个字段大家可以忽略
在Zookeeper中有一种同样的“设计模式”,就是可以通过在zookeeper中创建临时节点+事件监听机制,从而实现数据的实时动态感知,以/brokers/ids为例进行阐述:
-
Kafka broker进程启动时会向zookeeper创建一个临时节点/brokers/ids/{id},其中id为broker的编号
-
Kafka Broker进程停止后,创建的临时节点在broker与zookeeper的会话超时后会被自动删除,产生节点删除事件
-
Kafka controller 会自动监听/brokers/ids 目录的节点新增与删除事件,一旦broker下线、上线,controller都会实时感知,从而采取必要处理。
经过上面的初步介绍,Kafka对zookeeper的依赖还是非常大的,特别是Kafka控制器的选举、broker节点的存活状态等都依赖zookeeper。
Kafka 控制器可以看出是整个kafka集群的“大脑”,如果它出现异动,其影响范围之广,影响程度之大可想而知,接下来的故障分析会给出更直观的展现。
温馨提示:本文主要是一个故障分析过程,后续关于kafka控制器如何选举、leader_epoch副本同步机制等会在《Kafka原理与实战》专栏中一一介绍,敬请关注。
3、问题分析
一看到消息发送响应时间长,我的第一反应是查看线程栈,是不是有锁阻塞,但查看线程堆栈发现Kafka用于处理请求的线程池大部分都阻塞在获取任务处,表明“无活可干”状态:
 说明客户端端消息发送请求都没有到达Kafka的排队队列,并且专门用于处理网络读写的线程池也很空闲,那又是为什么呢?
说明客户端端消息发送请求都没有到达Kafka的排队队列,并且专门用于处理网络读写的线程池也很空闲,那又是为什么呢?消息发送端延迟超级高,但服务端线程又极度空闲,有点诡异?
继续查看服务端日志,发现了大量主题(甚至连系统主题__consumer_offsets主题也发生了Leader选举),日志如下:

核心日志:start at Leader Epoch 大量分区在进行Leader选举。
Kafka中中只有Leader分区能处理读、写请求,follower分区只是从leader分区复制数据,在Leader节点宕机后参与leader选举,故分区在进行Leader选举时无法处理客户端的写入请求,而发送端又有重试机制,故消息发送延迟很大。
那到底在什么情况下会触发大量主题进行重新选举呢?
我们找到当前集群的Controler节点,查看state-change.log中,发现如下日志:

出现了大量分区的状态从OnlinePartition变更为OfflinePartition。
温馨提示:根据日志我们可以去查看源码,找到输出这些方法的调用链,就可以顺藤摸瓜去找针对性的日志。
继续查看Controler节点下的controller.log中发现关键日志:

核心日志解读:
-
[Controller id=1] Broker failure callback for 8 (kafka.controller.KafkaController) 控制器将节点8从集群的在线中移除,控制器为什么会将节点8移除呢?
接下来顺藤摸瓜,去看一下节点8上的日志如下图所示:

核心日志解读:原来broker与zookeeper的会话超时,导致临时节点被移除。
先不探究会话为什么会超时,我们先来看一下会话超时,会给Kafka集群带来什么严重影响。
/brokers/ids下任意一个节点被删除,Kafka控制器都能及时得到,并执行对应的处理。
这里需要分两种情况考虑。
3.1 普通Broker节点被移除
处理入口为:KafkaController的onBrokerFailure方法,代码详情如下图所示:
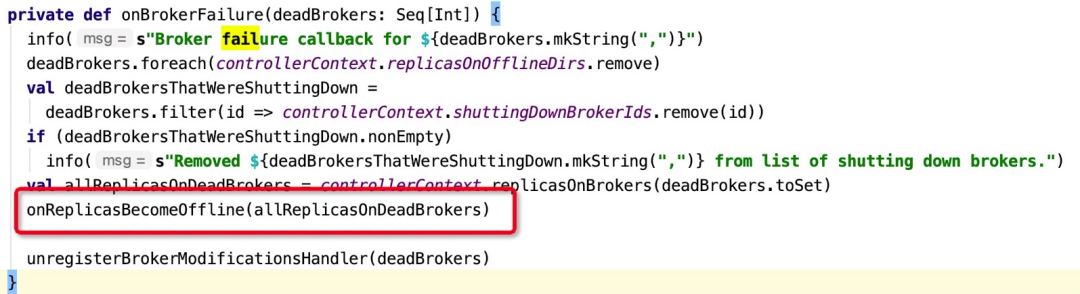
一个普通的broker在zk中被移除,Kafka控制器会将该节点上分配的所有分区的状态从OnlinePartition变更为OfflinePartition,从而触发分区的重新选举。
扩展知识点:__consumer_offsets分区如果进行Leader重新选举,大面积的消费组会触发重平衡,背后的机制:
消费组需要在Broker端进行组协调器选举,选举算法如下:消费组的名称的hashcode与主题 __ consumer_offsets的队列总数取模,取余数,映射成 __consumer_offsets 分区,该分区的leader在哪个broker节点,该节点则会充当消费组的组协调器。
一旦该分区的Leader发生变化,对应的消费组必须重新选举新的组协调器,从而触发消费组的重平衡。
3.2 Controller节点被移除
如果zookeeper中移除的broker id 为 Kafka controller,其影响会更大,主要的入口如下图所示:
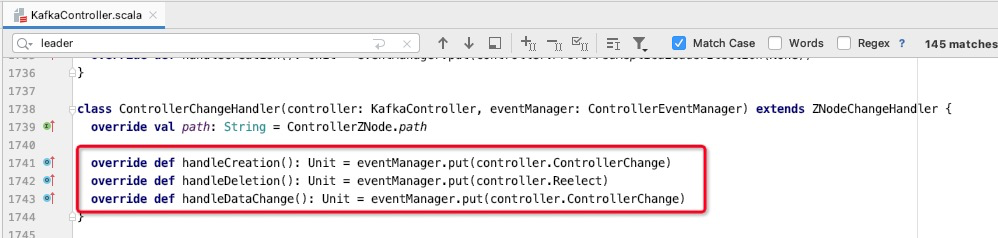
如果是controller节点会话超时,临时节点/controller节点会被删除,从而会触发Kafka controller选举,最终所有的broker节点都会收到节点/controller的删除、新增或节点数据变化的通知,KafkaController的onControllerFailover方法会被执行,与会将于zookeeper相关的事件监听器重新注册、分区状态机、副本状态机都会停止并重新启动,各个分区会触发自动leader分区选举。
可以这样形容:一朝天子一朝臣,全部重新来过。
3.3 zookeeper会话超时根因排查
查看服务端日志,可以看到如下日志:

核心日志解读:Closed socket connection for client ... 表示连接被客户端主动关闭。
那为什么客户端会主动关闭心跳呢?心跳处理的套路就是客户端需要定时向服务端发送心跳包,服务端在指定时间内没有收到或处理心跳包,则会超时。
要想一探究竟,唯一的办法:阅读源码 ,通过研读Zookeeper客户端源码,发现存在这样一个设计:客户端会把所有的请求先放入一个队列中,然后通过一个发送线程(SendThread)从队列中获取请求,发送到服务端,关键代码如下:
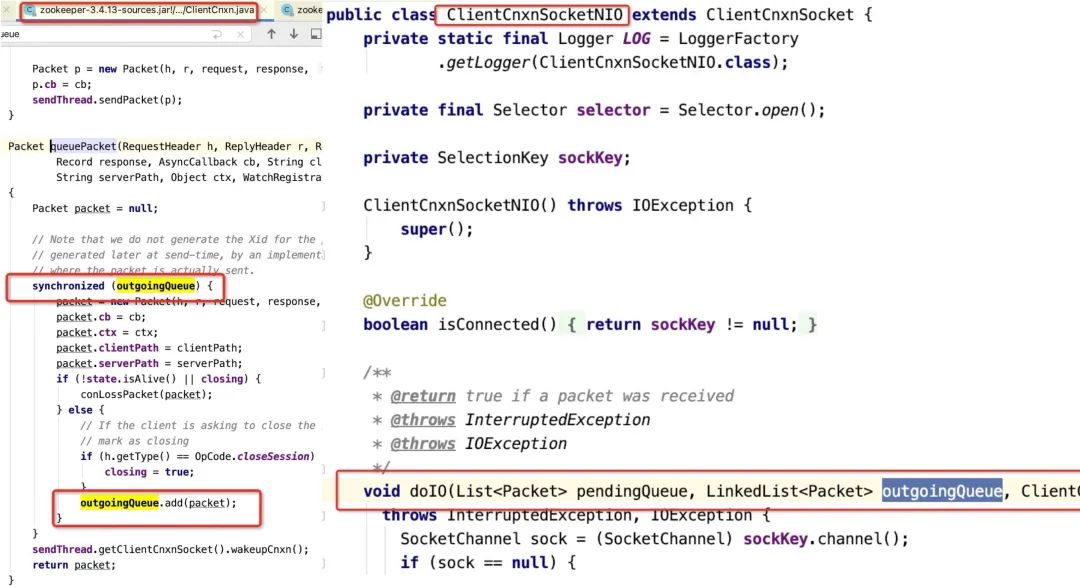
如果存在大量的zk更新操作,心跳包可能会处理不及时,而在出现zookeeper session会话超时之前,集群在大面积ISR扩张与收缩,频繁更新zk,从而触发了客户端端心跳超时,这个问题也可以通过如下代码进行复现:
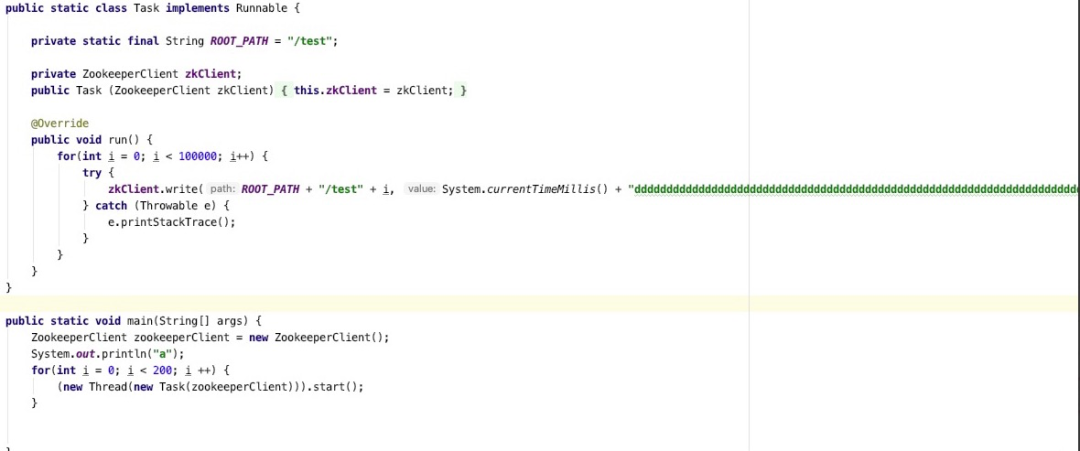
经过这波分析,由于zookeeper会话超时,导致大量分区重新选举,最终导致消息发送延迟很大,并且消费组大面积重平衡的根本原因就排查清楚了,本期分享就到此为止,我们下期见。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:「中间件兴趣圈」,在公众号中回复:「PDF」可获取大量学习资料,回复「专栏」可获取15个主流Java中间件源码分析专栏,另外回复:加群,可以跟很多BAT大厂的前辈交流和学习。


