
memory cgroup 泄露是 K8s(Kubernetes) 集群中普遍存在的问题,轻则导致节点内存资源紧张,重则导致节点无响应只能重启服务器恢复;大多数的开发人员会采用定期 drop cache 或者关闭内核 kmem accounting 进行规避。本文基于网易数帆内核团队的实践案例,对 memory cgroup 泄露问题的根因进行分析,同时提供了一种内核层面修复该问题的方案。
背景
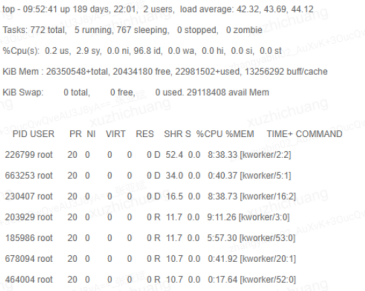
运维监控发现部分云主机计算节点,K8s(Kubernetes) 节点都有出现负载异常冲高的问题,具体表现为系统运行非常卡,load 持续在 40+,部分的 kworker 线程 cpu 使用率较高或者处于 D 状态,已经对业务造成了影响,需要分析具体的原因。
问题定位
现象分析
对于 cpu 使用率异常的问题,perf 是必不可少的工具。通过 perf top 观察热点函数,发现内核函数 cache_reap 使用率会间歇性冲高。
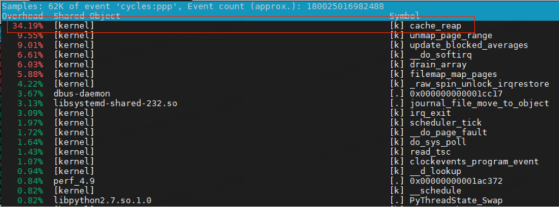
翻开对应的内核代码,cache_reap 函数实现如下:
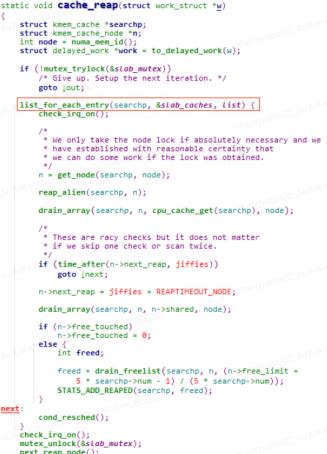
不难看出,该函数主要是遍历一个全局的 slab_caches 链表,该链表记录的是系统上所有的 slab 内存对象相关信息。
通过分析 slab_caches 变量相关的代码流程发现,每一个 memory cgroup 都会对应一个 memory.kmem.slabinfo 文件。
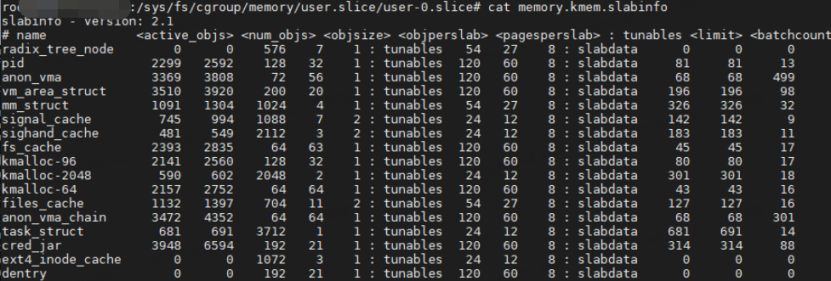
该文件里面记录的是各个 memory cgroup 组进程申请的 slab 相关信息,同时该 memory cgroup 组的 slab 对象也会被统一添加到全局的 slab_caches 链表中,莫非是因为 slab_caches 链表数据太多,导致遍历时间比较长,进而导致 CPU 冲高?
slab_caches 链表数据太多,那么前提肯定是 memory cgroup 数量要特别多,自然而然也就想到要去统计一下系统上存在多少个 memory cgroup,但当我们去统计/sys/fs/cgroup/memory 目录下的 memory cgroup 组的数量时发现也就只有一百个不到的 memory cgroup,每个 memory cgroup 里面 memory.kmem.slabinfo 文件最多也就包含几十条记录,所以算起来 slab_caches 链表成员个数最多也不会超过一万个,所以怎么看也不会有问题。

最终还是从最原始的函数 cache_reap 入手,既然该函数会比较消耗 CPU,那么直接通过跟踪该函数来分析究竟是代码里面什么地方执行时间比较长。
确认根因
通过一系列工具来跟踪 cache_reap 函数发现,slab_caches 链表成员个数达到了惊人的几百万个,该数量跟我们实际计算出来的数量差异巨大。
再通过 cat /proc/cgroup 查看系统的当前 cgroup 信息,发现 memory cgroup 数量已经累积到 20w+。在云主机计算节点上存在这么多的 cgroup,明显就不是正常的情况,即便是在 K8s(Kubernetes) 节点上,这个数量级的 cgroup 也不可能是容器业务能正常产生的。
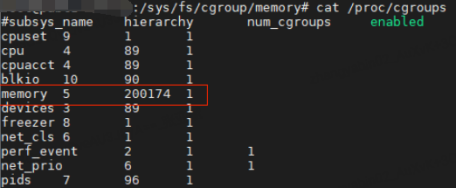
那么为什么/sys/fs/cgroup/memory 目录下统计到的 memory cgroup 数量和/proc/cgroups 文件记录的数量会相差如此之大了?因为 memory cgroup 泄露导致!
详细解释参考如下:
系统上的很多操作(如创建销毁容器/云主机、登录宿主机、cron 定时任务等)都会触发创建临时的 memory cgroup。这些 memory cgroup 组内的进程在运行过程中可能会产生 cache 内存(如访问文件、创建新文件等),该 cache 内存会关联到该 memory cgroup。当 memory cgroup 组内进程退出后,该 cgroup 组在/sys/fs/cgroup/memory 目录下对应的目录会被删除。但该 memory cgroup 组产生的 cache 内存并不会被主动回收,由于有 cache 内存还在引用该 memory cgroup 对象,所以也就不会删除该 memory cgroup 在内存中的对象。
在定位过程中,我们发现每天的 memory cgroup 的累积数量还在缓慢增长,于是对节点的 memory cgroup 目录的创建、删除进行了跟踪,发现主要是如下两个触发源会导致 memory cgroup 泄露:
-
特定的 cron 定时任务执行
-
用户频繁登录和退出节点
这两个触发源导致 memory cgroup 泄漏的原因都是跟 systemd-logind 登录服务有关系,执行 cron 定时任务或者是登录宿主机时,systemd-logind 服务都会创建临时的 memory cgroup,待 cron 任务执行完或者是用户退出登录后,会删除临时的 memory cgroup,在有文件操作的场景下会导致 memory cgroup 泄漏。
复现方法
分析清楚了 memory cgroup 泄露的触发场景,那就复现问题就容易很多:

核心的复现逻辑就是创建临时 memory cgroup,并进行文件操作产生 cache 内存,然后删除 memory cgroup 临时目录,通过以上的方式,在测试环境能够很快的复现 40w memory cgroup 残留的现场。
解决方案
通过对 memory cgroup 泄漏的问题分析,基本搞清楚了问题的根因与触发场景,那么如何解决泄露的问题呢?
方案一:drop cache
既然 cgroup 泄露是由于 cache 内存无法回收引起的,那么最直接的方案就是通过“echo 3 > /proc/sys/vm/drop_caches”清理系统缓存。
但清理缓存只能缓解,而且后续依然会出现 cgroup 泄露。一方面需要配置每天定时任务进行 drop cache,同时 drop cache 动作本身也会消耗大量 cpu 对业务造成影响,而对于已经形成了大量 cgroup 泄漏的节点,drop cache 动作可能卡在清理缓存的流程中,造成新的问题。
方案二:nokmem
kernel 提供了 cgroup.memory = nokmem 参数,关闭 kmem accounting 功能,配置该参数后,memory cgroup 就不会有单独的 slabinfo 文件,这样即使出现 memory cgroup 泄露,也不会导致 kworker 线程 CPU 冲高了。
不过该方案需要重启系统才能生效,对业务会有一定影响,且该方案并不能完全解决 memory cgroup 泄露这个根本性的问题,只能在一定程度缓解问题。
方案三:消除触发源
上面分析发现的 2 种导致 cgroup 泄露的触发源,都可以想办法消除掉。
针对第 1 种情况,通过与相应的业务模块沟通,确认可以关闭该 cron 任务;
针对第 2 种情况,可以通过 loginctl enable-linger username 将对应用户设置成后台常驻用户来解决。
设置成常驻用户后,用户登录时,systemd-logind 服务会为该用户创建一个永久的 memory cgroup 组,用户每次登录时都可以复用这个 memory cgroup 组,用户退出后也不会删除,所以也就不会出现泄漏。
到此时看起来,这次 memory cgroup 泄漏的问题已经完美解决了,但实际上以上处理方案仅能覆盖目前已知的 2 个触发场景,并没有解决 cgroup 资源无法被彻底清理回收的问题,后续可能还会出现的新的 memory cgroup 泄露的触发场景。
内核里的解决方案
常规方案
在问题定位过程中,通过 Google 就已经发现了非常多的容器场景下 cgroup 泄漏导致的问题,在 centos7 系列,4.x 内核上都有报告的案例,主要是由于内核对 cgroup kernel memory accounting 特性支持的不完善,当 K8s(Kubernetes)/RunC 使用该特性时,就会存在 memory cgroup 泄露的的问题。
而主要的解决方法,不外乎以下的几种规避方案:
-
定时执行 drop cache
-
内核配置 nokmem 禁用 kmem accounting 功能
-
K8s(Kubernetes) 禁用 KernelMemoryAccounting 功能
-
docker/runc 禁用 KernelMemoryAccounting 功能
我们在考虑有没有更好的方案,能在内核层面“彻底”解决 cgroup 泄露的问题?
内核回收线程
通过对 memoy cgroup 泄露问题的深入分析,我们看到核心的问题是,systemd-logind 临时创建的 cgroup 目录虽然会被自动销毁,但由于文件读写产生的 cache 内存以及相关 slab 内存却没有被立刻回收,由于这些内存页的存在,cgroup 管理结构体的引用计数就无法清零,所以虽然 cgroup 挂载的目录被删除了,但相关的内核数据结构还保留在内核里。
根据对社区相关问题解决方案的跟踪分析,以及阿里 cloud linux 提供的思路,我们实现一个简单直接的方案:
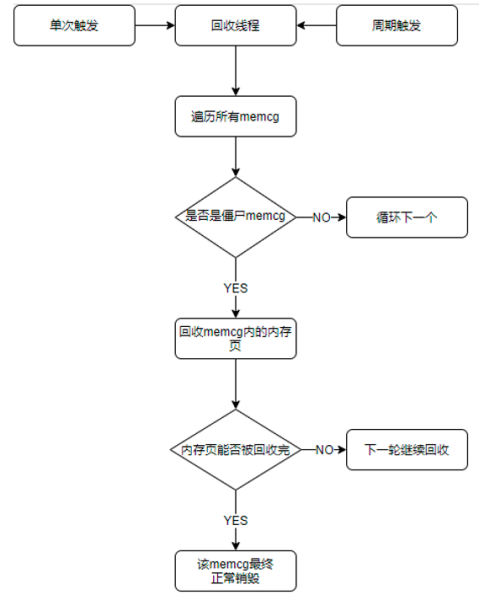
在内核中运行一个内核线程,针对这些残留的 memory cgroup 单独做内存回收,将其持有的内存页释放到系统中,从而让这些残留的 memory cgroup 能够被系统正常回收。
这个内核线程具有以下特性:
-
只对残留的 memory cgroup 进行回收
-
此内核线程优先级设置为最低
-
每做一轮 memory cgroup 的回收就主动 cond_resched(),防止长时间占用 cpu
回收线程的核心流程如下:
功能验证
对合入内核回收线程的内核进行功能与性能测试,结果如下:
-
在测试环境开启回收线程,系统残留的 memory cgroup 能够被及时的清理;
-
模拟清理 40w 个泄漏的 memory cgroup,回收线程 cpu 使用率最高不超过 5%,资源占用可以接受;
-
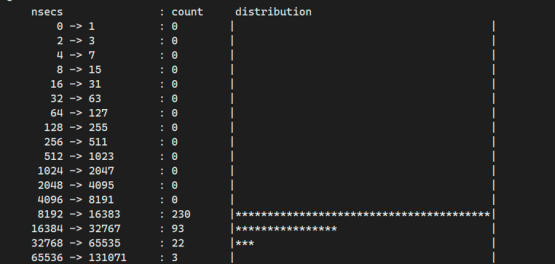
针对超大规格的残留 memory cgroup 进行测试,回收 1 个持有 20G 内存的 memory cgroup,核心回收函数的执行时间分布,基本不超过 64us;不会对其他服务造成影响;
开启内核回收线程后,正常通过内核 LTP 稳定性测试,不会增加内核稳定性风险。
可以看到通过新增一个内核线程对残留的 memory cgroup 进行回收,以较小的资源使用率,能够有效解决 cgroup 泄露的问题,这个方案已经在网易私有云大量上线使用,有效提升了网易容器业务的稳定性。
总结
以上是我们分享的 memory cgroup 泄露问题的分析定位过程,给出了相关的解决方案,同时提供了内核层面解决该问题的一种思路。
在长期的业务实践中,深刻的体会到 K8s(Kubernetes)/容器场景对 Linux kernel 的使用和需求是全方位的。一方面,整个容器技术主要是基于 kernel 提供的能力构建的,提升 kernel 稳定性,针对相关模块的 bug 定位与修复能力必不可少;另一方面, kernel 针对容器场景的优化/新特性层出不穷。我们也持续关注相关技术的发展,比如使用 ebpf 优化容器网络,增强内核监控能力,使用 cgroup v2/PSI 提升容器的资源隔离及监控能力,这些也都是未来主要推动在网易内部落地的方向。
作者介绍:张亚斌,网易数帆内核专家

