
谈一谈Linux让实时/高性能任务独占CPU的事原创
内容简介
本文主要讨论在高实时要求、高效能计算、DPDK等领域,Linux如何让某一个线程排他性独占CPU;独占CPU涉及的线程、中断隔离原理;以及如何在排他性独占的情况下,甚至让系统的timer tick也不打断独占任务,从而实现最低的延迟抖动。
阅读本文大约需要20分钟。
本文目录:
1. 工程需求
2. 用户态隔离
3. 内核态隔离
3.1 中断
3.2 内核线程
4. 最佳实践指南
Part 1
工程需求
在一个SMP或者NUMA系统中,CPU的数量大于1。在工程中,我们有时候有一种需求,就是让某个能够独占CPU,这个CPU什么都不做,就只做指定的任务,从而获得低延迟、高实时的好处。
比如在DPDK中,通过设置
GRUB_CMDLINE_LINUX_DEFAULT=“isolcpus=0-3,5,7”隔离CPU0,3,5,7,让DPDK的任务在运行的时候,其他任务不会和DPDK的任务进行上下文切换,从而保证网络性能最佳[1]。在Realtime应用场景中,通过isolcpus=2隔离CPU2,然后把实时应用通过taskset绑定到隔离的核:
taskset-c 2 pn_dev从而保证低延迟要求[2]。
Part 2
用户态隔离
这个地方,我们可以看出,它们统一都使用了isolcpus这样一个启动参数。
实践是检验真理的唯一标准,下面我们来启动一个8核的ARM64系统,运行Ubuntu,并指定isolcpus=2这个启动参数:

系统启动后,我们运行下面简单的程序(启动8个进程运行while死循环):
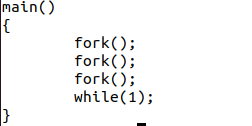
我们是8核的,现在又是运行8个进程,所以理论上来讲,负载均衡后,8个进程应该均分地运行在8个核上面,但是我们来看看实际的htop结果:

我们发现3(也就是CPU2)上面的CPU占用率是0.0%。这实证了CPU2已经被隔离,用户空间的进程不能在它上面跑。
当然,这个时候,我们可以通过taskset,强行把其中的一个a.out,绑定到CPU2上面去:
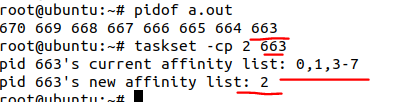
从上面命令的结果看出,663原本的affinity list只有0,1,3-7是没有2的,而我们强行把它设置为了2,之后再看htop,CPU2上面占用100%:
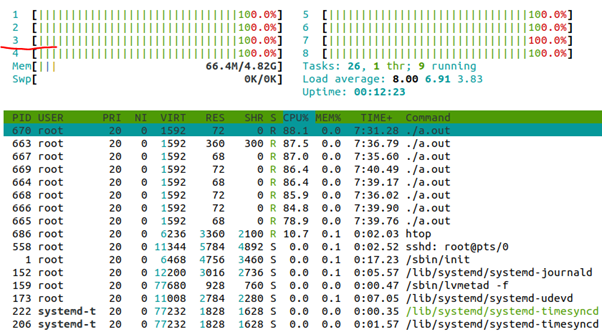
通过上面的实验,我们明显可以看出isolcpus=2使得CPU2上无法再运行用户空间的进程了(除非手动设置affinity)。
Part 3
内核态隔离
中断
但是,能在CPU2上面运行的,不是只有用户态的任务,还可以有内核线程、中断等,那么isolcpus=能否隔离内核线程和中断呢?
对于中断,我们特别容易查看,就是实际去验证每个IRQ的smp_affinity就好了:
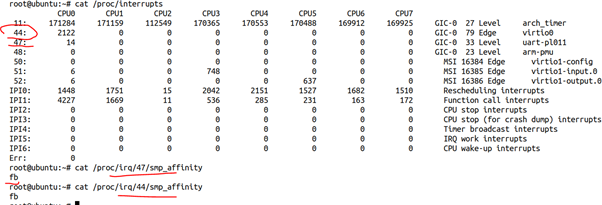
从上图明显可以看出,对于44、47号这种外设的中断,Linux内核把smp_affinity设置为了FB(11111011),明显避开了CPU2,所以,实际外设中断也不会在CPU2发生,除非我们强行给中断绑核,比如让44号中断绑定到CPU2:
echo 2 >/proc/irq/44/smp_affinity_list之后,我们发现44号中断在CPU2可以发生:
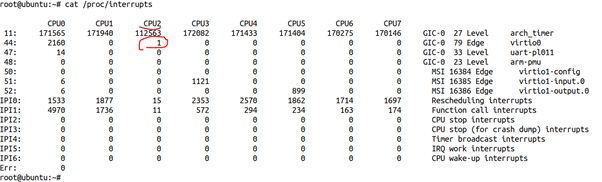
但是,系统的timer中断、IPI,由于是Linux系统的运行基石,实际还是要在CPU2上面运行的。这里面最可能给任务带来延迟抖动的,自然是timer tick。
下面我们重点探讨下tick的问题,由于Linux一般情况下,已经配置IDLE状态的NO_HZ tickless,所以CPU2上面什么都不跑的时候,实际timer中断几乎不发生。
下面,我们还是在isolcpus=2的情况下,运行前面那个8个进程的a.out,默认情况下没有任务会占用CPU2。通过先后运行几次cat /proc/interrupts | head 2,我们会看到其他core的timer中断频繁发生,而CPU2几乎不变,这显然是IDLE时候的NO_HZ在发挥省电的作用:

但是,一旦我们放任务到CPU2,哪怕只是放1个,就会发现CPU2上面的timer中断开始增加:
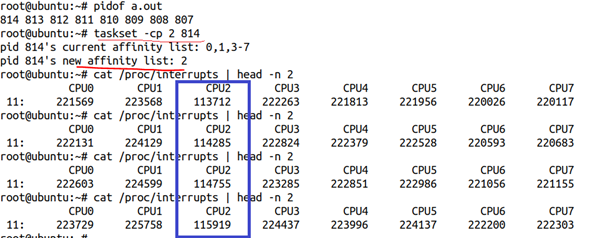
这说明一点,哪怕隔离的CPU上面只有一个线程去跑,timer tick就会开始跑,当然,这个timer tick也会频繁打断这一个线程,从而造成大量的上下文切换。你肯定会觉得Linux怎么这么傻,既然只有一个人,那也没有时间片分片的必要,不需要在2个或者多个任务进行时间片划分地调度,为啥还要跑tick?其实原因是我们的内核默认只是使能了IDLE的NO_HZ:
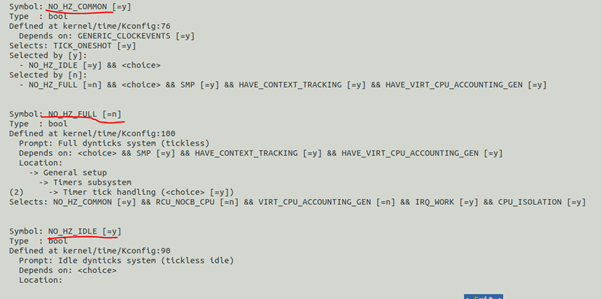
我们来重新编译一个内核,使能NO_HZ_FULL:
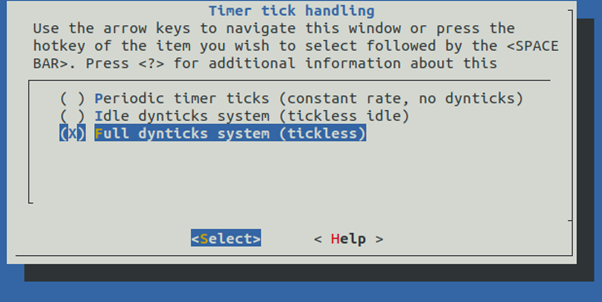
当我们使能了NO_HZ_FULL后,Linux支持在CPU上仅有1个任务的时候,是可以NO_HZ的。但是有2个就傻眼了,所以这个“FULL”也不是真地FULL[3]。这当然也可以理解,因为有2个就涉及到时间片调度的问题。什么时候应该使能NO_HZ_FULL,内核文档Documentation/timers/no_hz.rst有明确地“指示”,只有在实时和HPC等的场景,才需要,否则默认的NO_HZ_IDLE是你最好的选择:
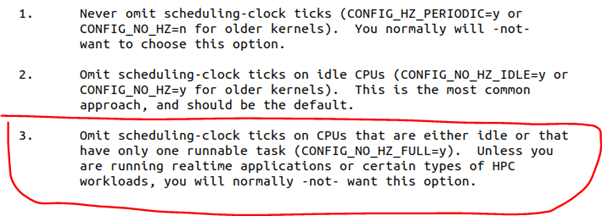
我们重新编译了内核,选中了NO_HZ_FULL,下面启动Linux,注意启动的时候参数添加nohz_full=2,让CPU2支持NO_HZ_FULL:

重新运行CPU2只有一个任务的场景,看看它的timer中断发生情况:
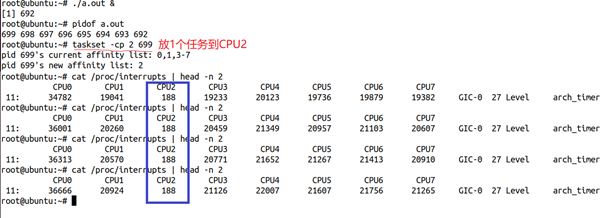
发现CPU2上面的tick稳定在188上面,这样相信你会更加开心,因为你独占地更加彻底了!
下面,我们再放一个task进去CPU2,有2个任务的情况下,CPU2上面的timer tick开始增加:
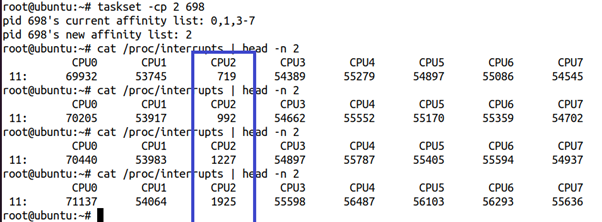
不过,这或许不是个问题,因为我们说好了“独占”,1个任务独占的时候,timer tick不来打扰,应该已经是非常理想的情况了!
内核态线程
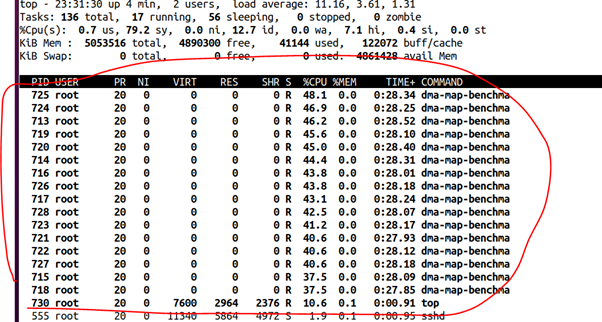
内核态的线程其实和用户态差不多,当它们没有绑定到隔离的CPU的时候,是不会跑到隔离CPU运行的。下面用笔者在内核里面添加的dma_map_benchmark来做实验[4],开启16个内核线程来进行DMA map和unmap(注意我们只有8个核):
./dma_map_benchmark -s 120 -t 16我们看到CPU2上面的CPU占用也是0:

内核里面的dma_map_benchmark线程在狂占CPU0-1, 3-7,但是就是不去占CPU2:
但是,内核线程如果用kthread_bind_mask()类似API把线程绑定到了隔离的CPU,则情况就不一样了,这就类似用taskset把用户态的任务绑定到CPU一样。
Part 4
最佳实践指南
对于实时性要求高、高性能计算等场景,如果要让某个任务独占CPU,最理想的选择是:
1. 采用isolcpus隔离CPU
2. 将指定任务绑定到隔离CPU
3. 小心意外地把中断、内核线程绑定到了隔离CPU,排查到这些“意外”分子
4. 使能NO_HZ_FULL,则效果更佳,因为连timer tick中断也不打扰你了。
参考文献
[1]http://doc.dpdk.org/spp-18.02/setup/performance_opt.html
[2]https://rt-labs.com/docs/p-net/linuxtiming.html
[3]https://lwn.net/Articles/549580/
[4]
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=65789daa80
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=7679325702



