
QPS过万,Redis大量连接超时怎么解决?原创
之前负责的一个服务总是在高峰时刻和压测发生大量的redis连接超时的异常redis.clients.jedis.exceptions.JedisConnectionException,根据原有的业务规则,首先会从数据库查询,然后缓存到redis中,超时时间设置为3分钟。
并且由于业务的特性,本身未做降级、限流等处理措施,而在巅峰的QPS基本上快达到20000的样子,虽然这个现象只是单纯的一个异常,并不会导致整个主链路的流程不可用,但是我们还是要找出问题的原因并且解决。
首先我们找到负责Redis同学排查,他们告诉我Redis现在很稳定,没有问题,以前现在未来都不会出问题,出了问题肯定是你们自己的问题。
... ...
说的好有道理,我竟无力反驳,真是让人两个头一个大。
这样的话,我们就只能去找找自身的原因了。
排查思路
查看异常分布
首先根据经验,我们看看自己的服务器的情况,看下异常到底出现在哪些机器,通过监控切换到单机维度,看看异常是否均匀分布,如果分布不均匀,只是少量的host特别高,基本可以定位到出现问题的机器。
诶,这就很舒服了,这一下子就找到了问题,只有几台机器异常非常高。
不过不能这样,我们继续说排查思路......
Redis情况
再次按照经验,虽然负责redis的同学说redis贼稳定巴拉巴拉,但是我们本着怀疑的态度,不能太相信他们说的话,这点很重要,特别是工作中,同学们,不要别人说啥你就信啥,要本着柯南的精神,发生命案的时候每个人都是犯罪嫌疑人,当然你要排除自己,坚定不移的相信这肯定不是我的锅!
好了,我们看看redis集群是否有节点负载过高,比如以常规经验看来的80%可以作为一个临界值。
如果有一个或少量节点超过,则说明可能存在热key问题,如果大部分节点都超过,则说明存在redis整体压力大问题。
另外可以看看是否有慢请求的情况,如果有慢请求,并且时间发生问题的时间匹配,那么可能是存在大key的问题。
嗯... ...
redis同学说的没错,redis稳如老狗。
CPU
我们假设自己还是很无助,还是没发现问题在哪儿,别急,接着找找别人的原因,看看CPU咋样,可能运维偷偷滴给我们把机器配置给整差了。
我们看看CPU使用率多高,是不是超过80%了,还是根据经验,我们之前的服务一般高峰能达到60%就不错了。
再看看CPU是不是存在限流,或者存在密集的限流、长时间的限流。
如果存在这些现象,应该就是运维的锅,给我们机器资源不够啊。
GC停顿
得嘞,运维这次没作死。
再看看GC咋样。
频繁的GC、GC耗时过长都会让线程无法及时读取redis响应。
这个数字怎么判断呢?
通常,我们可以这样计算,再次按照我们一塌糊涂的经验,每分钟GC总时长/60s/每分钟GC个数,如果达到ms级了,对redis读写延迟的影响就会很明显。
为了稳一手,我们也要对比下和历史监控级别是否差不多一致。
好了,打扰了,我们继续。
网络
网络这块我们主要看TCP重传率,这个基本在大点的公司都有这块监控。
TCP重传率=单位时间内TCP重传包数量/TCP发包总数
我们可以把TCP重传率视为网络质量和服务器稳定性的一个只要衡量指标。
还是根据我们的经验,这个TCP重传率越低越好,越低代表我们的网络越好,如果TCP重传率保持在0.02%(以自己的实际情况为准)以上,或者突增,就可以怀疑是不是网络问题了。
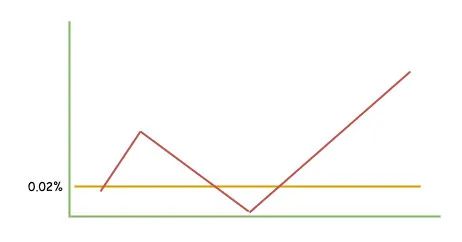
比如这张图一样,要是和心电图一样,基本上网络问题就没跑了。
容器宿主机
有一些机器有可能是虚拟机,CPU的监控指标可能不准确,特别是对于IO密集型的情况会有较大差异。可以通用其他手段来查询宿主机的情况。
最后
根据一系列的骚操作,我们根据定位到的机器然后排查了一堆情况,最终定位到是网络问题,有单独的几台机器在高峰时期TCP重传率贼高,最后根据运维提供的解决方案:【重启有问题的机器】,我们很顺利的就解决了这个问题。
但是,这毕竟是治标不治本的办法,最终怎么解决的?
在我的另外一篇文章我有写到了,下面贴出原文。
----------------------------------------------------------------
你应该从网上看过太多的文章说缓存穿透怎么解决?无非就是布隆过滤器,缓存空值什么的。
但是,更深入的一个问题,缓存空值有没有问题?如果缓存的空值太多怎么办?
如果用的redis,那么太多的空值会不会打爆你的redis?如果用的本地缓存,会不会打爆你的内存?继而引发的问题就是还是会打爆你的数据库。
从线上问题说起
前不久,我们线上环境压测,在QPS压倒2W之后RT达到了几十秒,排查后发现是redis的连接数不够导致大量的连接超时。
经过考虑之后,我们最终决定弃用redis缓存的方案,改为本地缓存,因为我们缓存的都是一些配置信息,实际上几个月都不太可能修改,而redis配置的连接数是200,5分钟超时,数据量实际上也就只有几千条而已,实际上来说并没有很大的必要,本地缓存完全就可以解决问题了。
本地缓存使用Guava的LoadingCache实现。
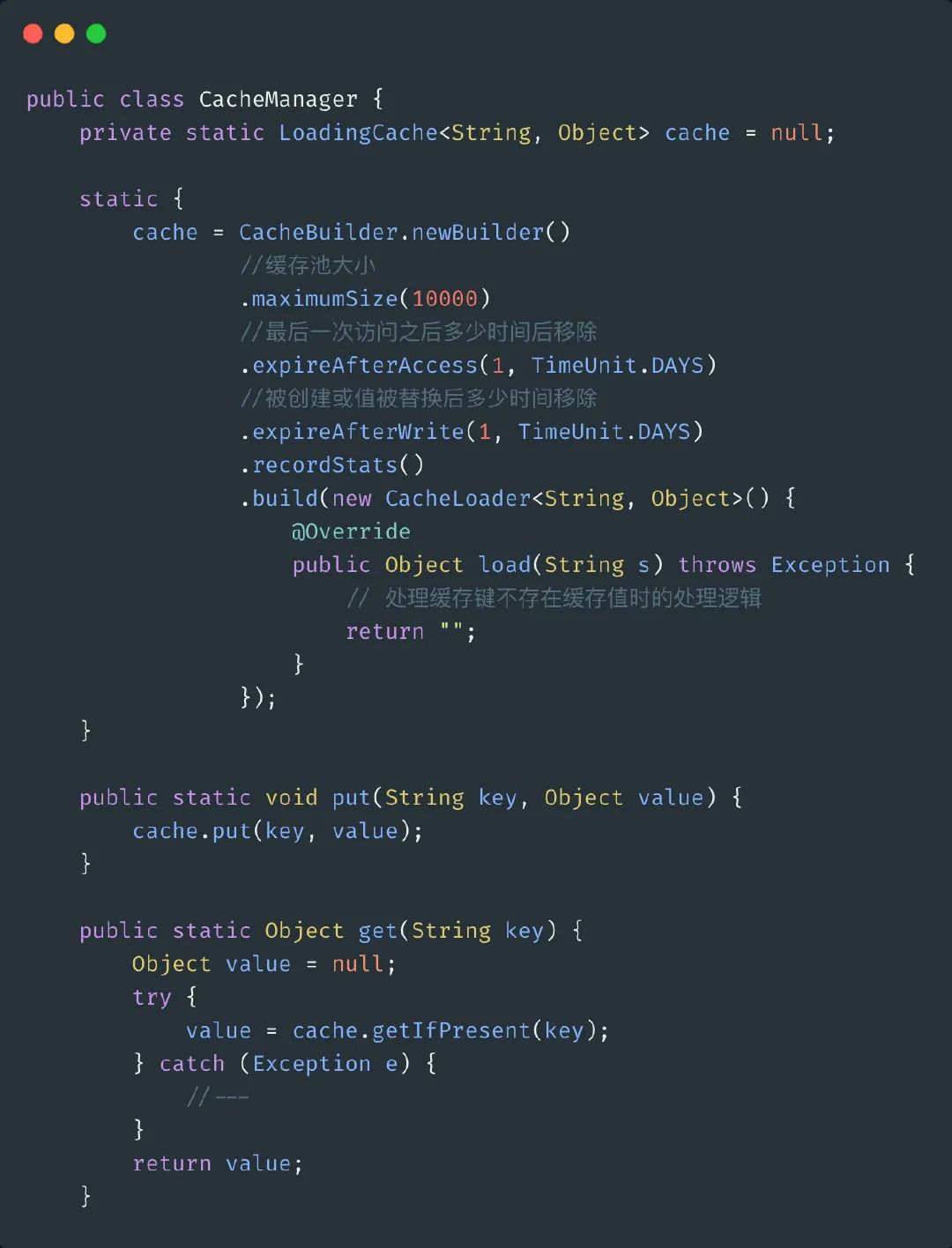
但是修改完之后,压测之后还是发现有接口全部走到数据库查询,先排查代码,是否是代码的BUG导致实际没有生效,后来发现实际上发生了缓存穿透,压测使用了一些数据库中不存在的记录,导致了穿透的问题,实际上这个问题在使用redis的时候也一直存在,只是由于连接数的问题一直没有发现而已。
接下来就是考虑怎么解决的问题?
由于我们都是缓存的一些配置信息,几千条数据而已,最终考虑简单解决的办法。直接把所有的key全部从数据库查出来缓存下来,查数据库之前直接根据key过滤一把,如果不存在就直接返回,不要走数据库查询了。
当然,这是由于我们的场景比较简单,这样直接处理就行了,那么,如果再复杂一点,比如上亿的缓存数据呢?
解决方案
前置过滤
如果说类似我这种比较简单的一些缓存,使用我上面说的解决方案也可以,还有一些缓存的key是比如ID之类,也可以根据一定的范围规则去提前过滤,比如缓存的key明确知道在1-10万的范围之后,那么过滤掉在这个范围之外的请求直接返回就可以了。
当然,很明显这种简单的规则过滤适用于数据量不是很大,并且数据不会频繁发生改变的情况。
布隆过滤器
对于上述场景,因为数据量很小,简单的代码实现缓存即可,如果说数据量很大的话,比如有一亿个key,使用布隆过滤器就是个更优解。
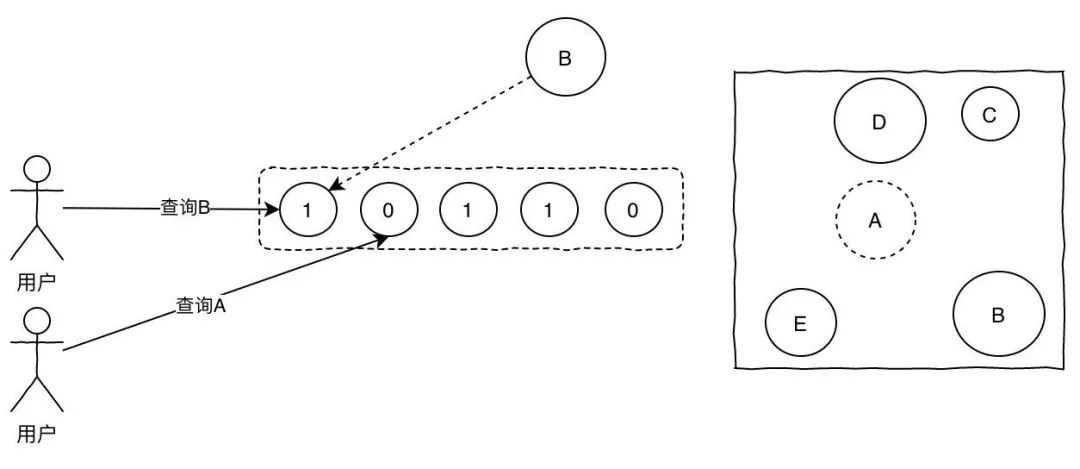
我们可以每天定时把所有的配置信息从数据库中查询出来构建成bitmap。
关于布隆过滤器我前面的文章也有写过,贴上之前的图一张,如果查询的位置都是1的话说明key存在,反之只要有一个0则说明肯定不存在。
使用布隆过滤器的缺点也很明显,存在一定概率的误判。当然,既然用了,对于误判比例、内存占用等等问题应该事先评估好。
缓存空值
这个是网上说烂的问题,但是缓存空值的空值太多明显也是有问题的,再进一步解决方案就是快速过期。
一般来说,普通的缓存的写法如下,先查缓存,如果缓存存在则直接返回,如果缓存没有则去数据库查询,结果不是空就保存到缓存中。

改进版的写法就是缓存空对象,针对空的数据,设置过期时间,比如10分钟,快速过期,防止太多的空值问题。

但是这个解决方案仍然有点小问题,就是短暂的数据不一致的问题。
想象一下如果缓存的空值这时候实际上已经有值了,那么在过期时间的这段时间内就可能存在短暂的数据不一致。
总结
缓存穿透的问题总结下来就是三点,这三个方式不是说是隔离的解决方案,他们可以结合在一起使用。
首先看数据量,如果数据量很小并且没有频繁变更的话,选择前置过滤的方式,根据具体的业务规则来处理就可以。
如果数据量大的话,可以选择使用布隆过滤器,但是存在一定概率的误判。
通过前置的拦截,应该拦截住大部分的流量,避免直接打爆数据库。
最后,可以使用缓存空值并且设置快速过期的方式来作为一个兜底的方案。
如果还有问题,那么就是限流、降级了。


