
记一次产线报错引发关于CurrentHashmap使用的思考原创
最近笔者所在公司的业务团队在使用dubbo-admin进行应用发布的时候出现了一个问题,应用发布结束后,上线应用流量的时候某个节点的部分接口进行上线操作第一次会失败,但是同一批的相同节点其他接口上线正常,再点下上线逻辑后就可以正常上线了。
这个问题其实影响并不严重,业务可以通过多次点击上线按钮进行规避,但是由于当天是发布日,发布需求比较多,很多业务都出现了这个问题。所以笔者对这个问题产生了兴趣,开始进行排查,最后发现是dubbo-admin官方的一个使用currentHashMap的不规范的bug,当然现在的版本已经修复了这个问题,笔者在这里记录下问题排查的过程,以及相关结论。
一.日志排查
因为dubbo-admin并不是笔者管理的项目,所以一开始笔者是在日志反面进行排查,看看能不能发现一些端倪。经过一番搜索,发现在日志中充斥着一个报错:
ERROR grayscale - [DUBBO] Provider was changed!, dubbo version: 2.5.7.9, current host: xxxxx
java.lang.llegalStateException: Provider was changed!
........(后面是栈信息)
之后笔者又下载了我们公司使用的dubbo-admin相关版本的代码,先从第一个报错的堆栈信息中找看看有没有什么相关蛛丝马迹。
在这里由于代码比较多,篇幅有限,笔者通过一张图展示下dubbo-admin的上线相关流程:
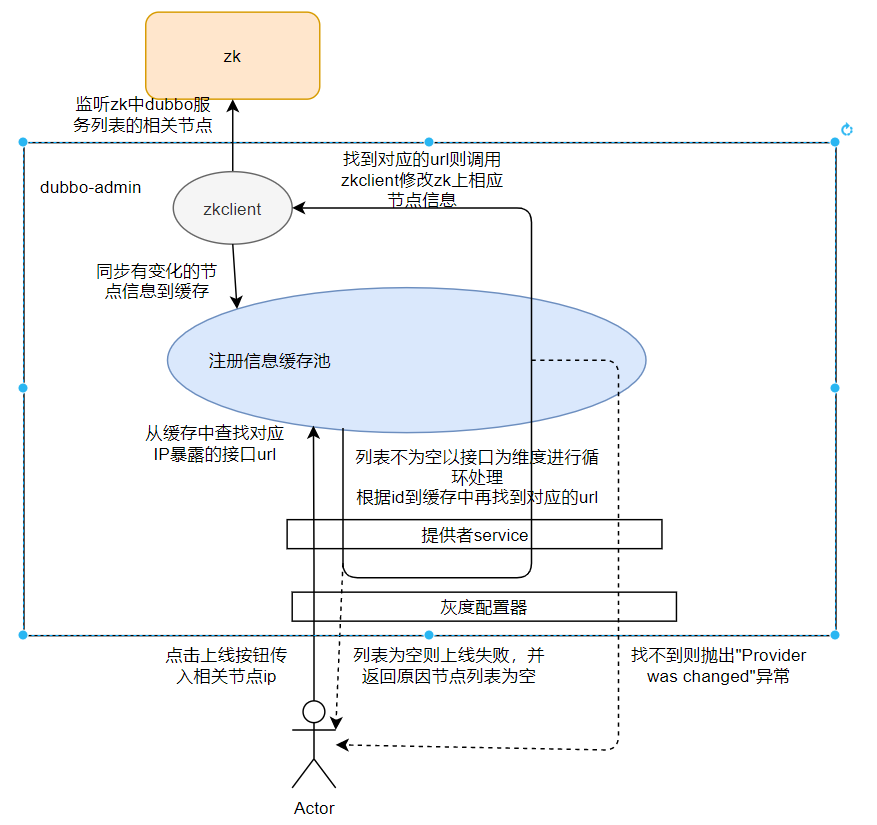
(1) 首先用户点击上线按钮,会经过灰度配置器调用提供者service去缓存中查询对应IP暴露的所有接口的url,若查不到则直接返回列表为空。
(2) 若查到数据则以接口为维度进行循环处理,根据每个提供者的id(这个id需要注意下,后面会提到)再次去缓存中找对应的url,如果找不到则抛出第一种异常,即Provider was changed。
(3) 若找到则通过zkclient更新相关节点信息。
大家可以看到这个流程里面查了两次缓存,如果在第一次缓存中查到,而在这期间zk上的数据有所变更,zkclient更新了本地缓存,那么第二次查缓存的时候就会查不到,可能会造成上线失败,起初很多小伙伴都以为是这个原因导致上线失败。但是笔者将日志和上线时间进行了比对,发现在业务点击上线按钮的时间段,期间并没有抛出Provider was changed异常,也就是说并不是第二次查缓存造成的报错。
而且在这期间,有一次诡异的空指针异常,这个空指针异常并没有打印出相关堆栈信息,所以问题一度陷入僵局,无从排查。
二.从源码出发
既然日志看不出问题,笔者从公司仓库中拉去了线上运行的代码版本,希望从代码中可以找到问题。经过对代码的排查,笔者发现zkclient从zk中获取的dubbo注册节点相关信息会保存在本地的缓存池中(即刚刚图中的注册信息缓存池),而这个缓存的结构其实是:
ConcurrentMap<String, ConcurrentMap<String, Map<Long, URL>>> registryCache
可以看到,是三个Map的嵌套,笔者敏锐的注意到,前两层均是ConcurrentMap,而第三层则是一个普通的map,那么在高并发情况下,对第三层map进行修改,就可能导致某个线程从map中获取value获取不到,也就是说可能有导致报空指针异常的可能。
既然确定了目标,笔者就从两个方向开始查找,分别是缓存更新的时机和获取缓存的位置
1.缓存更新的时机
缓存是三层map进行嵌套,前两层都是concurrentMap,我们就可以忽略,重点来看第三层map的更新,相关的伪代码如下:
//创建一个新的一层map,遍历url信息将其加入构建的新map中
ConcurrentHashMap<String, ConcurrentHashMap<String, Map<Long, URL>>> newMap1 = new ConcurrentHashMap();
for(url : urls) {
ConcurrentHashMap<String, Map<Long, URL>> newMap2 = new ConcurrentHashMap();
Map<String, Map<Long, URL>> cacheMap2 = newMap2.get(key1);
if (newMap2 == null) {
newMap2 = new HashMap<String, Map<Long, URL>>();
newMap1.put(key1, newMap2 );
}
Map<Long, URL> newMap3 = newMap2.get(key2);
if (newMap3 == null) {
newMap3 = new HashMap<Long, URL>();
newMap2 .put(key2, newMap3);
}
//注意,这里修改了key
newMap3.put(ID.incrementAndGet(), url);
}
//替换缓存中的map
for (Map.Entry<String, Map<String, Map<Long, URL>>> newEntry1 : newMap1.entrySet()) {
String newKey1 = newEntry1.getKey();
ConcurrentMap<String, Map<Long, URL>> cacheMap2 = cacheMap1.get(newKey1);
if (cacheMap2 == null) {
cacheMap2 = new ConcurrentHashMap<String, Map<Long, URL>>();
cacheMap1.put(category, services);
}
//注意这里直接putAll会直接将新的url全部替换掉
cacheMap2.putAll(newEntry1.getValue());
}
由此可以确定由于第三层map的id被修改掉了,而且后面是全部替换,所以在多次读取缓存的时候可能会存在获取到null的风险。
2.获取缓存的位置
经过排查笔者发现在上线流程中除了刚刚列出的两次查询缓存的操作,还存在一次比较隐秘的查询操作,即存在第三次查询缓存的操作,相关代码如下:
//OverrideServiceImpl类的方法
public void deleteOverride(Long id) {
//第三次从缓存中查询
URL oldOverride = findOverrideUrl(id);
if (oldOverride == null) {
throw new IllegalStateException("Route was changed!");
}
registryService.unregister(oldOverride);
}
//这个方法的调用详细信息
URL findOverrideUrl(Long id) {
return getUrlFromOverride(findById(id));
}
private URL getUrlFromOverride(Override override) {
//笔者猜测可能在这里抛出空指针异常
return override.toUrl();
}
至此笔者发现,这个空指针异常完全有可能是这个位置抛出的,之后笔者发现dubbo-admin这个项目是运行在tomcat容器中,而tomcat的默认配置会把经常抛的异常进行jit的优化,不打印栈信息,所以笔者又去归档日志中查找了这个空指针异常的栈信息,果然是在笔者猜测的这一行抛出空指针异常。
三.后续
之后笔者到dubbo-admin的github地址上查看了这部分的历史代码,发现这个问题已经被官方当作Bug进行修复了:
连接地址:https://github.com/apache/dubbo/commit/1f2dcbe208691fe4aad59d01f9f5a89c26c10373#
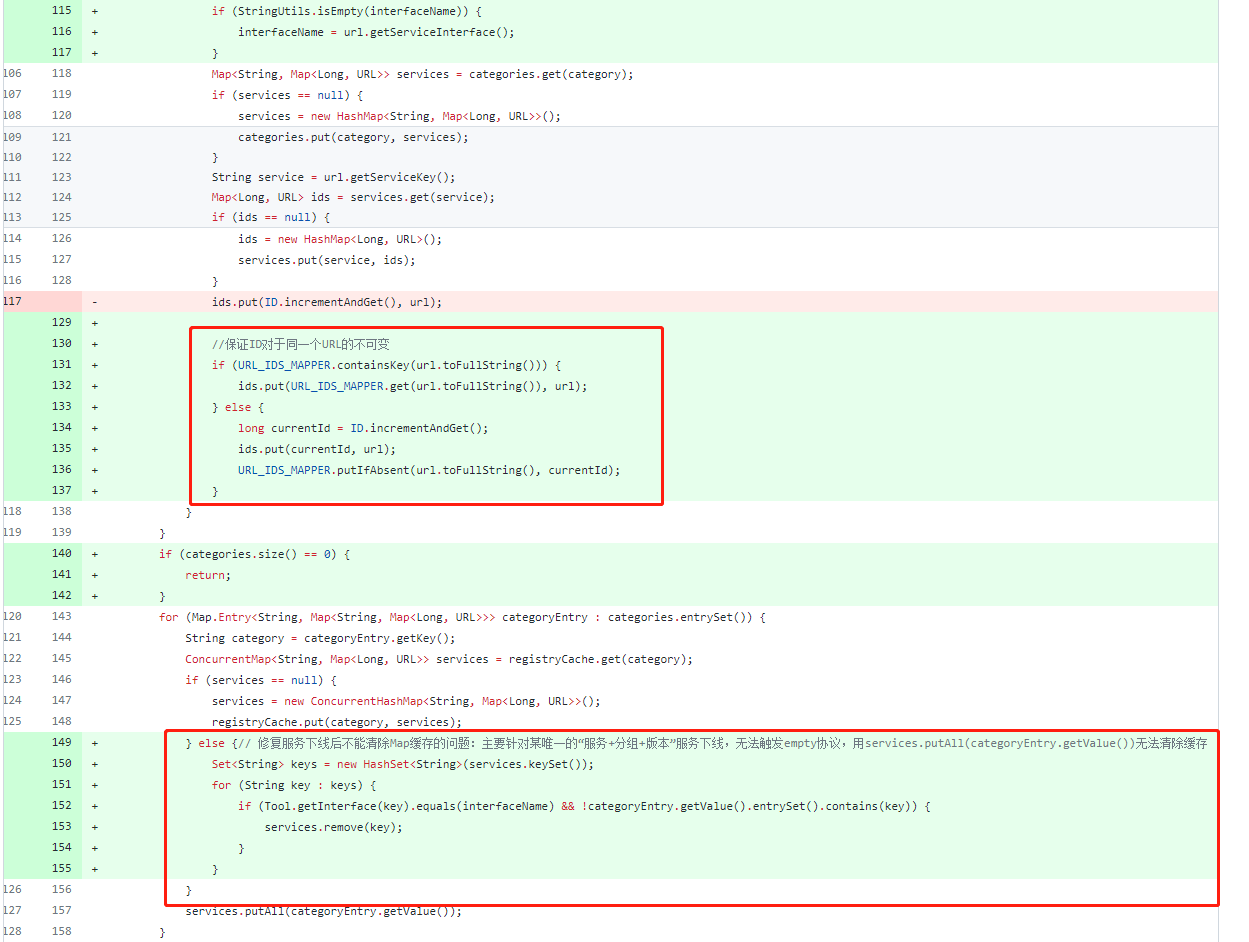
我们可以看到官方加入了一个id和url的映射,保证每个Url对应的id都不变,这样才多次读取缓存的时候就不会造成读不到的问题。
从本次问题的解决中,我们可以看到ConcurrentHashMap虽然是是线程安全的,但是其内部的数据并不是线程安全的,我们最好不要轻易修改其内部数据的相关信息,如果是必须要修改其内部数据的需求下,就需要考虑多线程下其内部数据存在线程不安全的场景。

