
一行小错为何产生巨大破坏-Facebook史诗级故障大反思原创
弱小从来不是生存的障碍,傲慢才是。10月4日FaceBook发生了一次史诗级中断事故,故障期间FaceBook所有旗下APP全面对外服务中断,而且故障的时间长达7个小时之久。根据Facebook最新的声明来看,故障的原因是由于工程师错误地发出了一条指令,切断了Facebook的数据中心“在全球范围内的所有网络连接”。

恰恰是这条简单的指令,造成的影响却是史诗级别的,本次宕机事故非常彻底,甚至Facebook自己的内网也完全报废,无法访问。笔者看到事件解决过程中不少运维方面的大牛都直接把故障的原因定位到了DNS和BGP方面。
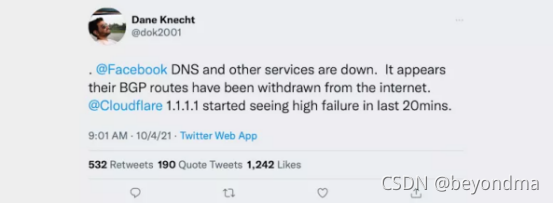
从Cloudflare的博客中也能看到,问题的原因也确实出在了BGP指令方面,不过我们要问的是为什么这样一条小小的指令会造成如此之大的影响。
route-views>show ip bgp 185.89.218.0/23
% Network not in table
route-views>
上一次Facebook的全面中断事件还要追溯到7年的2014年6月当时Facebook在APP更新版本时出现了一些问题,随后就有一些用户开始无法登陆Facebook,不过Facebook方面很快就找到了问题所在并进行了修复,并在半小时之内就让服务100%恢复了正常。
这次史诗级故障也不是脆弱的BGP协议第一次出现问题,就在2020年1月23日,所有后缀为.net的域名也出现无法解析的情况,经DNS顶级根服务运营商ISC调查,发现.net域名缺失了关键的A记录和AAAA记录,所有.net后缀的互联网地址从ISC的F根服务器全部消失了,接下来美国宇航局(NASA)运营的E根服务器也遇到了类似的问题。
那次故障中ISC定位问题的时间也很快,在5分钟内就迅速将问题定位在他们与Cloudflare合作运营的节点上,后来Cloudflare很快查明原因是由于他们刚刚发布的变更代码所造成的问题。但最终问题的解决也花了近两个小时的时间,因为撤回导致该问题的BGP通告,出乎意料的长。
通过对比我们可以看到,本次Facebook的故障无论是从影响程度,还是故障时间上讲都堪称是负面教材的典型,而历史一再告诉我们,只要能从历史经验中总结一点教训就能避免悲剧的发生,因此复盘这次史诗级的故障,对于我们来说肯定也会是大有裨益。
BGP协议简介
BGP边界网关协议是EGP外部网关协议的一种, 顾名思义BGP处理外部网络区域的之间路由信息的协议,其主要功能是与其他网络自治区的BGP协议系统交换网络路由信息。我们看到EGP相对的IGP内部网关协议,拥有众多储如RIP、OSPF、IS-IS、IGRP、EIGRP的协议族实现不同。EGP家族当中几乎只有BGP这一根独苗是可用的,BGP几乎是唯一一个能够处理独立路由域间的多路连接的协议。
我们举个例子来说明一下这个BGP协议,比如互联网上有7个独立的网络自治区域AS (Autonomous System),他们分别是AS1-AS7,这7个AS之间相互的物理连接情况用橙色线段表示如下:
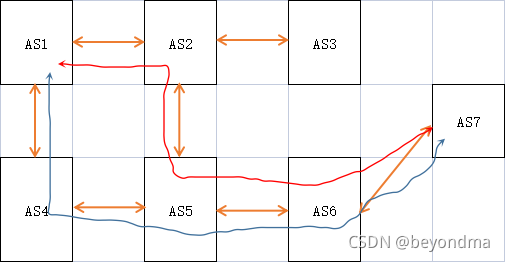
那么如果AS1区域内的设备想要与AS7区域内的设备产生连接,那么具体的路由路径应该选择AS1-AS4-AS5-AS6-AS7的蓝色路径,还是选择AS1-AS2-AS35-AS6-AS7的红色路径就是BGP协议要解决的核心问题,其实BGP之类的路由协议从宏观层面来看都有点像旅游规划,也就是可以把问题转化为从AS1到AS7的道路中哪条道路最快。BGP协议通过一系列的报文,Internet发布其前缀路由信息,并维护一个有限状态机,并以此来完成路由策略的收敛,但如果发布了错误的通告信息,那么就没有人能够知道如何连接这个错误区域了。当然本文不是要介绍BGP协议,这里各位读者对于BGP的有关概念性有所认识就可以了。
事件处理故障复盘
正如Facebook公告所说,事故的一开始,Facebook已经停他们DNS前缀路由的BGP通告也就是说Facebook的DNS无法访问,也就是说一条错误的指令让Facebook整体下线了。
route-views>show ip bgp 129.134.30.0/23
% Network not in table
route-views>
在故障期间通过dig、nslookup等命令解析Facebook的DNS域名全部返回SERVFAIL,而且正如我们上文介绍,如果发布了错误的BGP通告,那么没有人能够再从互联网上找到你,这和人工破坏了Facebook数据中心的连向互联网的光纤线路,从结果上看没有任何本质区别。
根据CloudFlare的博客显示,Facebook的故障差点把整个互联网搞崩,因为Facebook用户太多了,用户在无法正常登陆APP时会疯狂的发起重试,而且由于Facebook域名解析缓存已经在各级DNS服务器上全部失效了,这就给根DNS也就是1.1.1.1造成了巨大的压力。据说这使1.1.1.1的DNS解析查询的速度比平时高出30倍,所幸1.1.1.1顶住了压力,Facebook故障期间绝大多数的DNS解析请求的返回速度都稳定在10毫秒左右,否则一旦根DNS也崩溃那么后果将不堪设想。
最终在7个小时之后,Facebook终端重新向互联网通告了他们的路由,至此服务才最终恢复。
通过本次事件我们能学到什么
笔者相信以Facebook那些大牛人物的实力,从发现故障到定位故障原因的时间不会超过1分钟,甚至很有可能在刚刚指行完那条错误的BGP通告命令之后就发现问题了,但是故障依旧持续了长达7个小时。再结合Facebook内网全部中断的细节,那么我们可以推出隐藏在这背后的重要结论,那就是相关的错误命令把Facebook的VPN通道也全部影响了,我们知道Facebook目前在疫情的影响下,美国区的员工还处在远程办公的状态,也就是说在错误指令生效之后,远程运维工程师自身的VPN以及逃生通道也全部失效了,而数据中心现场值班的人员可能只会加电、重启等简单操作,甚至不排除现场人员连登陆到核心网络设备的权限都没有,一切都得指望远程运维的人员到现场解决了。
假设自己不出现低级失误,才是最大的低级错误:从上述分析中我们可以看出,Facebook的网络工程师对于自身的能力太过自信了,以至于他们可能就没有认真分析过回退方案的可行性,而故障发生之后才发现网络设备已经无法通过远程方式登陆了,回退方案执行的前提已经崩溃。因此在发布任何版本之前都要根据其造成的最大负面影响制订预案,假定自身不会出现低级失误的想法是绝对错误的。
逃生通道是最后生命线,必须严格保持独立:从故障的时间上看,远程登陆的逃生通道也一定是受到了影响,从这里我们能吸取到的教训就是一定要在平时做好逃生通道的可用性验证,并且要尽量保证逃生通道的独立性,不能把逃生和日常运营的通道混为一谈。
————————————————
版权声明:本文为CSDN博主「beyondma」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/BEYONDMA/article/details/120634403

