
对话悟道·文澜团队:像人类一样认识世界,AI需要哪些底层思维?原创
近几年,多模态已经成为自然语言处理(NLP)领域的热点研究方向之一。得益于深度学习的兴起,大数据+大模型的双轮模式推动人工智能实现了跨越式发展。但大量实验证明,仅依靠“炼大模型”仍不足以解决通用人工智能(AGI)的常识问题。
此外,计算机视觉、自然语言处理、语音识别等技术日益成熟,使“多模态”信息融合的优势进一步凸显。去年年初,OpenAI发布多模态大规模预训练模型CLIP和DALL·E,在语言理解和图像生成方面刷新SOTA,验证了多模态在处理NLP任务中潜力。
在国内,北京智源研究院近日发布全球最大规模预训练语言模型“悟道2.0”,其1.75万亿参数在业内引起不小的震撼。延续GPT-3的“暴力美学”,悟道2.0的效率更高,性能更佳,一举拿下了9项Benchmark。
其中,以多模态为核心的预训练模型悟道·文澜,在语义理解、视觉-语言检索方面的能力同样令人惊艳。据官方介绍,文澜2.0实现7种不同语言的生成和理解,创下多语言预训练模型的最高记录,同时,凭借更多的常识储备,在图文检索、图像问答等任务上达到了世界领先水平。

文澜的定位是解决多模态之间的语义融合问题。“我们希望创造出世界上最大、性能最佳的通用多模态模型,为各种现实应用场景赋能。”中国人民大学高瓴人工智能学院执行院长、文澜研发团队总负责人文继荣教授告诉AI科技评论。
悟道·文澜是中国人民大学高瓴人工智能学院与北京智源研究院合作,联合中科院和清华大学共同开展的大规模预训练模型研究项目。目前有3位核心负责人、8位科研人员,27位高校学生参加整个项目的统筹与研发工作。
文继荣教授与同为人大高瓴人工智能学院的宋睿华副教授和卢志武教授为团队的核心负责人。近日,AI科技评论有幸采访到了三位专家,与他们聊了聊文澜背后的技术与展望。
从左到右依次为:金琴、宋睿华、文继荣、卢志武

仿人类认知思维,多模态加速推进AGI
2021年1月6日,OpenAI同时发布两大多模态预训练模型DALL·E和CLIP——前者可基于文本生成图像,后者能够完成图像与文本类别的匹配。殊不知,在人们惊呼自然语言与视觉的次元壁被打破时,在中国同步开发并在多项指标上超过OpenAI的预训练语言模型——悟道.文澜已经诞生。
2020年10月,智源研究院与各大科研院所的AI专家们召开内部会议,商讨人工智能下一阶段的研发方向,其中,研发文本与图像互通的“多模态”模型以高票数胜出。同月,文澜项目正式启动。三个月后,在智源研究院提供算力、数据等资源的支持下,文澜模型研发成功。
自GPT-3问世之后,国内众多AI专家已经敏锐地察觉到,OpenAI下一步的目标一定是多模态。类似于大模型,多模态将成为业内下一个热点研究方向。那么,文澜的研发初衷只是为了与OpenAI一争高下,或者在学术界占据高地吗?
究竟为何要研究多模态,为何要研发文澜模型?
自然语言处理是人工智能领域的基础研究,也是实现通用人工智能的关键性挑战,之所以在文澜中融入多模态,实现文本与图像的连接,文继荣教授表示,
多模态不仅要解决NLP的问题。我们认为,多模态更符合人类认知世界的方式。人类通过视觉和听觉感知物理世界的过程是多模态的,通过模仿这一过程有可能从根本上解决“AI学习智能行为,而非智能本身”的问题。
人工智能的终极目标是:让机器拥有和人一样的理解与思考能力。要想达到这一目标,需要无限接近于人类的认知方式。我们生活在一个多模态的交互环境中,听到的声音、看到的实物、闻到的味道等,不同的模态信息让我们更全面和高效地了解周围的世界。
模态(Modality)是一个广泛的概念,它代表每一种信息的来源或者形式,上述提到的听觉、视觉、嗅觉代表不同的模态感知方式;信息的媒介中的语音、视频、图像、文字等代表不同的模态数据。
在自然语言理解任务中,融入图像模态有助于AI像人类一样学习和理解文本信息,反之亦然。
文继荣教授举例说,我们经常用一些抽象的词语来形容人或物,比如慈祥、俊朗、活力。如果只有纯文字,一个呀呀学语的小孩子可能很难理解什么是慈祥,但如果给她看一张老奶奶的图片,她可能很快就能理解。AI模型就是这样一个小孩。
更重要的是,有了视觉模态的加持,AI模型还能极大地扩展语义信息、增强图文理解能力。
据悉,在文澜1.0版时,研发团队已经对多模态模型进行了测试,看看它到底比单模态多了哪些信息。下面是两张测试图:左边是用BERT文本预训练模型得到的结果,右边是用UNITER多模态预训练模型得到的结果。
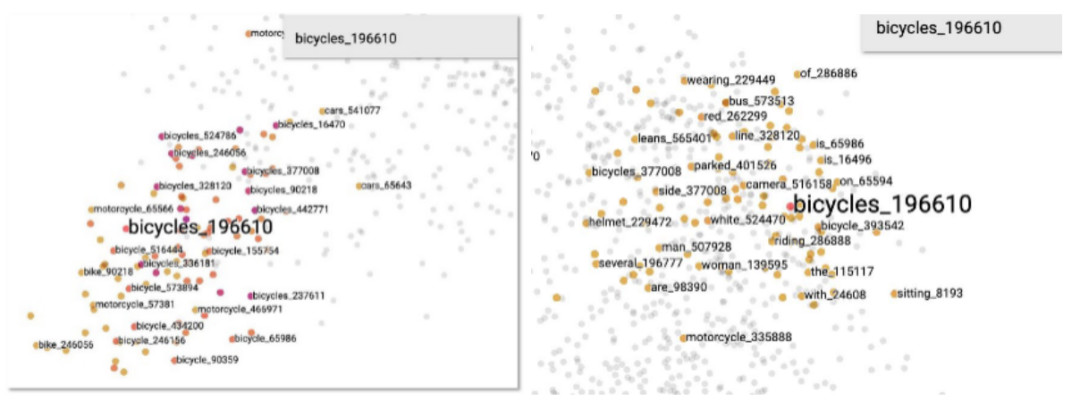
如果输入“自行车”一词,通过文本数据训练的AI,周围出现了类似于自行车,摩托车,汽车等强相关词汇。
而利用多模态数据进行训练的AI,其周围出现了一些,如“骑”、“男人、女人”、“头盔”,“停车”一类更丰富的弱相关词汇,甚至还出现了“on”表示“位于车上”的词。
这里提到的强相关与弱相关的概念,是文澜研发团队首次认识到并明确提出的,也是文澜2.0取得突破性进展的本质原因之一。
“弱相关”关系,文澜模型的底层思维
多模态从2010年后开始进入Deep Learning阶段。
在此期间,业界和学术界推出的多模态预训练模型不在少数,且多出自国内外顶级科研机构。现阶段,主流的多模态NLP模型,除了DALL·E和CLIP外,还有阿里与清华联合研发的M6、百度研发的ERNIE-ViL等等。
众多高性能模型中,后来居上的文澜为何成了世界级“领跑者”?
文澜模型结构负责人卢志武教授对此介绍了三点,第一,文澜是首创双塔结构(Bridging Vision and Language ,BriVL-2)进行预训练的模型,与传统单塔相比,BriVL-2在图像和文本之间建立了一种“弱相关”假设。

如上,给定一张“生日蛋糕”的图片,强相关模型可能会输出——生日蛋糕的蜡烛在燃烧,本文内容基本与图片保持一致,而弱相关则可能输出——今天的减肥计划又泡汤了,它尝试从更高的内涵层次上理解图像信息。
换言之,弱相关使文澜模型对文本/图像信息的理解不仅局限于“等价”关联,而是进一步扩展到了“场景”关联、“因果”关联等。
事实上,多模态之间的语义融合问题一直是人工智能领域一项极具挑战性的工作。2005年,《Nature》期刊曾发表一篇文章,表明人类对同一实体的图像和文字两种模态的认知是在同一神经元上激活的,二者会被映射到同一个空间。
类似地,为了模仿人脑的建模过程,AI模型在预训练过程中,通常会事先把数据集中的图像编码成一个高维向量,当用户输入文字时,再将文字向量映射到同一个空间,最后通过向量检索,获取相应的图片。
该过程的关键在于,文本和图像的语义信息是否实现对齐、融合。
文继荣教授介绍称,这项任务看似简单,实则难度极高。而文澜成功将两种模态的语义映射到了同一空间,并获得相同的表达。这项突破性进展,攻克了计算机视觉研究长期以来无法解决的难题。
第二,文澜2.0所使用的训练图文数据集从3000万升级到了6.5亿,且数据全部抓取自互联网。
据悉,DALL·E采用的是Image数据集,其文本数据多为一些名词概念,相对固化,而文澜的6.5亿图文数据来自现实世界,自然而真实。更重要是,文澜的弱相关性假设,使数据无需标注成为可能。
第三、文澜支持整个句子的理解,而非关键词。这是它与浏览器搜索最显著的区别。比如,在《布灵的想象世界》中输入“忧郁的蛋糕”,它会呈现一个以黑色调为背景的蛋糕图片。宋睿华教授介绍称,文澜能够通过抽象性文字呈现出一种氛围,而不是仅focus一个关键词。
基于以上核心能力,文澜已经具备文检索图、文生成图、图检索文、图生成文四种功能。目前研发团队利用图检索文、文检索图两项核心功能开发了应用小程序《AI心情电台》和《布灵的想象世界》,首次实现了高效的跨模态检索。

此外,中科院计算所团队还在文澜多模态的基础上开发了应用《只言片语》,考察文澜模型的语言理解能力与人类玩家的相似度。这个应用包括“默契大考验”和“看看谁懂我”两种模式,是首个AI加持的在线桌游,也是一种新模式的图灵测试。

在游戏的过程中,一名玩家随机挑选一张图片,并给出与之相关的文字描述。另一位玩家根据出题人玩家的描述从文澜给出的干扰项中挑选出正确的图片。如果两位玩家的图片不一致,说明文澜对文本的精准理解对人类产生了干扰,即通过了图灵测试。

以往的图灵测试都是以数据标注的形式进行,过程通常枯燥乏味;“只言片语“采用小游戏的形式,在给玩家带来乐趣的同时,通过测试模型检索到的图片是否能够迷惑人类,从而评估了图文匹配模型的能力。
逼近图灵测试,探秘AI“潜意识”
没有常识的AI,永远无法实现真正的智能。
2021北京智源大会,宋睿华教授在题为《我们赖以生存的意义和超大规模多模态预训练》的主旨演讲中,提出“仅通过文字,AI很难像人类那样将语言理解成意义”,她大胆预言:对多模态的研究可能会带来自然语言理解的重大突破, 多模态将是AI开启常识之门的钥匙。

在迈向通用人工智能的路上,常识是AI必须要解决的基本问题。然而,以GPT-3为代表的超大规模预训练模型,并不足以解决这一问题。尽管“大模型”带来了超乎想象的性能表现,但它与图灵测试仍相距甚远。
其实,GPT-3并非完全不具备常识,而是受限于单模态的信息获取方式,导致其常识性不足。众所周知,大部分常识是不言而喻的,我们并不会直接表达出来,比如太阳有几只眼睛?铅笔与烤面包机哪一个更重?换言之,凡是没有采用文本方式进行表达的常识,都不能为GPT-3所学习。

毫无疑问,相比于单模态,文澜能够从图文融合的多模态中获取到更多的常识。文继荣教授表示,常识是无穷无尽,文澜从图文模态学习到了哪些常识,不能学习哪些常识,目前仍在进一步研究中。但可以确定的是,多模态为AI拥有常识提供了一条最富潜力的路径。
区别于科学知识,常识主要来源于人们对一般日常生活的感性认识和经验总结。由于未通过图灵测试,GPT-3被认为不具备人类的感知思维,它无法超越数据本身,也无法拥有组合性推理的能力,其生成能力不过是统计层面的“复制粘贴”能力。
为了测试文澜是否学到了语义信息,并拥有了真正的理解能力。研发团队对文澜的“潜意识”过程进行了可视化,即告诉文澜一个概念,让它以图像的形式呈现出“大脑”对这一概念最原始的理解与想象。例如,输入梦境、科学、自然。

如上图,经过多模态预训练后的文澜,基本能够“看到”抽象的人类概念,并且不同于CLIP模型,这些可视化结果未经人为干预和手工挑选,是模型对输入概念的第一反应。这说明,文澜的生成能力并非基于单纯的数据统计,而是对文字本身有了内涵上的理解。
除了抽象概念,文澜也能对句子、诗词想象出意境。如输入【大漠孤烟直,长河落日圆】,虽然没有明显的孤烟、长河、落日等意象,但整体棕黄色的氛围确实体现了大漠的环境。

通过神经元可视化,我们得以窥见文澜的内心世界,了解其最原始的、最真实的、在“潜意识”中对于输入文本的独特理解。文澜团队介绍称,不同于图文检索能力,神经元可视化展现了文澜在艺术生成方面的潜力,下一阶段团队将重点培养其审美能力,使其创作出更好的艺术作品。
总结
遵循“炼大模型”的基本原则,文澜使用6.5万亿真实的图文对进行预训练,参数量达到了10亿。在此基础上,它尝试从多模态场景出发,模拟人类的认知思维,独创性地提出了基于跨模态对比学习的双塔结构。
该结构利用图-文的弱相关性假设,为文澜提供了更丰富的语义信息和更强大的理解能力,并通过神经元可视化得到了最佳验证。此外,在公开VQA数据集Visual7W的视觉问答测试任务中,文澜能额外带来8%的增长,展示了多模态预训练的常识学习能力。
总结来看,悟道·文澜在研发过程中重点关注三个方面,一是如何利用现有的单模态预训练大模型的研究成果;二是如何更好地刻画互联网上图文弱相关的关系;三是如何让模型学习到更多常识;针对以上问题,文澜已经揭开了答案的一角。
来源:雷锋网
https://www.leiphone.com/category/academic/OZX7crDDxJfVLOf4.html

