
Redis OOM(out of memory)内存占用过高,故障分析过程。原创
本文正在参加「Java应用线上问题排查经验/工具分享」活动
先点赞再看,养成好习惯
背景
全国最大的短信平台,大家都用过我们的产品。数据量比较大,最多时候一天近7亿条短信。
简单介绍一下redis(我们平台用的是codis管理redis集群)
简单来说 redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向。另外,redis 也经常用来做分布式锁。redis 提供了多种数据类型来支持不同的业务场景。除此之外,redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
回归正题
先看图
这是2019年8月3日的问题,这个问题导致整个平台半瘫痪3天。平台是8月2日晚上11点版本升级的,然后8月3日,8月4日,8月5日连续半瘫痪3天,才找到问题原因。是该平台迄今为止最大的事故。由于基础不扎实导致排查问题缓慢。
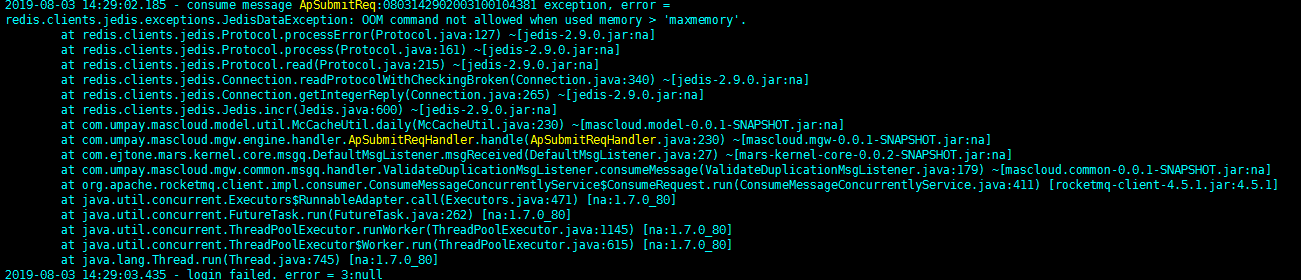
排查思路:
1.发现该问题立马先查redis集群内存使用情况,发现已经达到设置的临界值了。于是迅速调整redis集群内存大小,增大原有内存二分之一,从新启动集群,该问题立马解决,平台趋于稳定运行状态。
2.由于平台的数据量基本是在早上8点到晚上8点之间。周六日的数据量会小于周一到周五的数据量,8月3日大约15点左右平台恢复稳定运行。一直到8月4日早上9点,又开始出现该问题,发现调整后的redis内存依旧不够使用。迅速就调整redis集群的淘汰策略。(1)在内存达到阈值后删除长时间未使用的缓存数据。(2)加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键。然后重启集群平台稳定运行。
3.8月5日工作日第一天,短信量增大,原本的淘汰策略已经不好使了。开始 调整应用入redis的数据的过期时间,由原来的24小,调整为半小时,只运行了1个小时。此刻整个平台已经瘫痪,因为redis是必经之路。开始手动清理redis的内存数据。集群状态开始出现问题。原本的3主3从变成4主2从。然后查了4主的IP,有两个IP是相同的,但是无论怎么kill其中一个都杀不掉。迅速就搭建了另外一套redis集群把所有项目的连接全部切到新集群上,业务恢复,但是历史数据丢失。
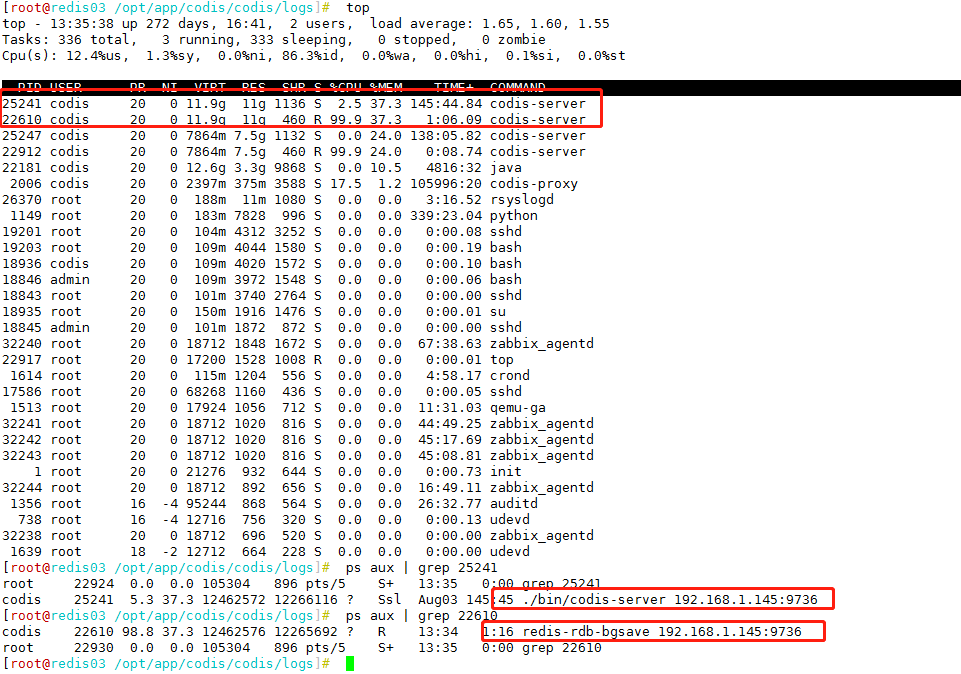
4.此刻迅速抓包分析(应用到redis之间的数据包)。运维查老集群的进程状态
发现
主进程codis-server 占用12G内存,同步fork 数据进程rdb占用 12G;才导致redis缓存被击穿。抓包分析看到应用和redis交互的数据包中,99%的数据在操作相同的事情(数据格式都一样)。然后查代码分析消息队列去重导致的该问题。立马修改代码恢复业务。
问题解决
1.我们在分配redis集群内存时一定要考虑fork进程占用的数据,他和内存数据占用的内存是相同的。fork进程主要是往硬盘写数据的进程,就是持久化。不要以为服务器内存16G,就直接分配redis内存12个G,这样就不对了。
2.定时去清理过期的缓存,合理规划数据的过期时间。
3.一定要评估当前业务的数据量占用redis的内存空间大小。(这个通过压测可以得到准确数据)
4.备用集群一定要提前准备着以防不时之需。
5.防止内存穿透和雪崩。(具体该方法下期再具体讲)


