
RocketMQ 在使用上的一些排坑和优化原创
前言:
RocketMQ 在我们的项目中使用非常广泛,在使用的过程中,也遇到了很多的问题。比如没有多环境的隔离,在多个版本同时开发送测的情况下,互相干扰严重。RocketMQ 的投递可能会失败,导致丢失消息。另外开源版本的 RocketMQ 不支持任意时间精度的延时消息,仅支持特定的 level。在使用的过程中,我们做了一些针对性的优化,整理出了这篇文章。
通过阅读这篇文章,你会了解到这些知识
RocketMQ 多环境隔离方案尝试
基于 RocksDB 的消息“可靠”投递方案
基于 RocksDB 和 RocketMQ 实现任意延时的时延消息
RocketMQ 多环境隔离
因为我们有很多功能需求会并行开发和送测,开发和测试的环境各有三四套之多,假设现在我们有三个版本在同时开发,对于同一个 topic,dev1 开发环境产生的消息可能会被 dev3 开发环境消费,这两个环境消费端的代码可能不一致,造成没有办法完成这部分功能的测试,这种情况下,开发人员苦不堪言,经常需要去下线掉其它环境的消费端才能继续进行开发测试,如下图所示。
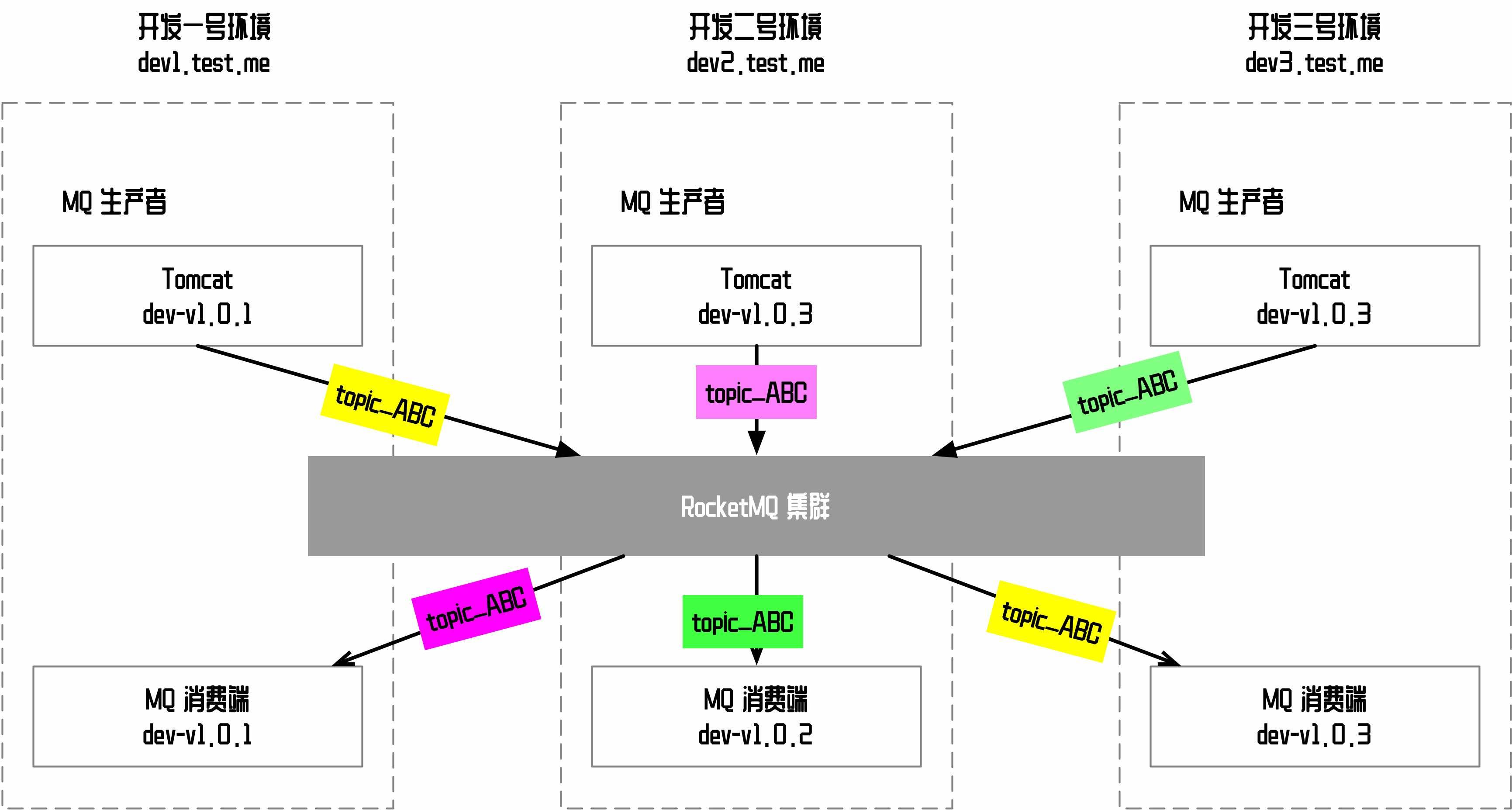
为了解决这个问题,一开始是想在 topic 上下功夫,通过修改 Producer 端,让每个环境的 topic 统一加一个环境后缀,这样 topic_ABC 在 dev1 环境就会变为 topic_ABC_dev1。这种方式理论上也可以解决,只是需要创建较多 topic,代价比较高,改动量大。
后面采用的方案是给每个环境分配独立的 RocketMQ 队列来实现,下面为了讲述的简单起见,这里只给每个环境分配一个队列,如下所示。
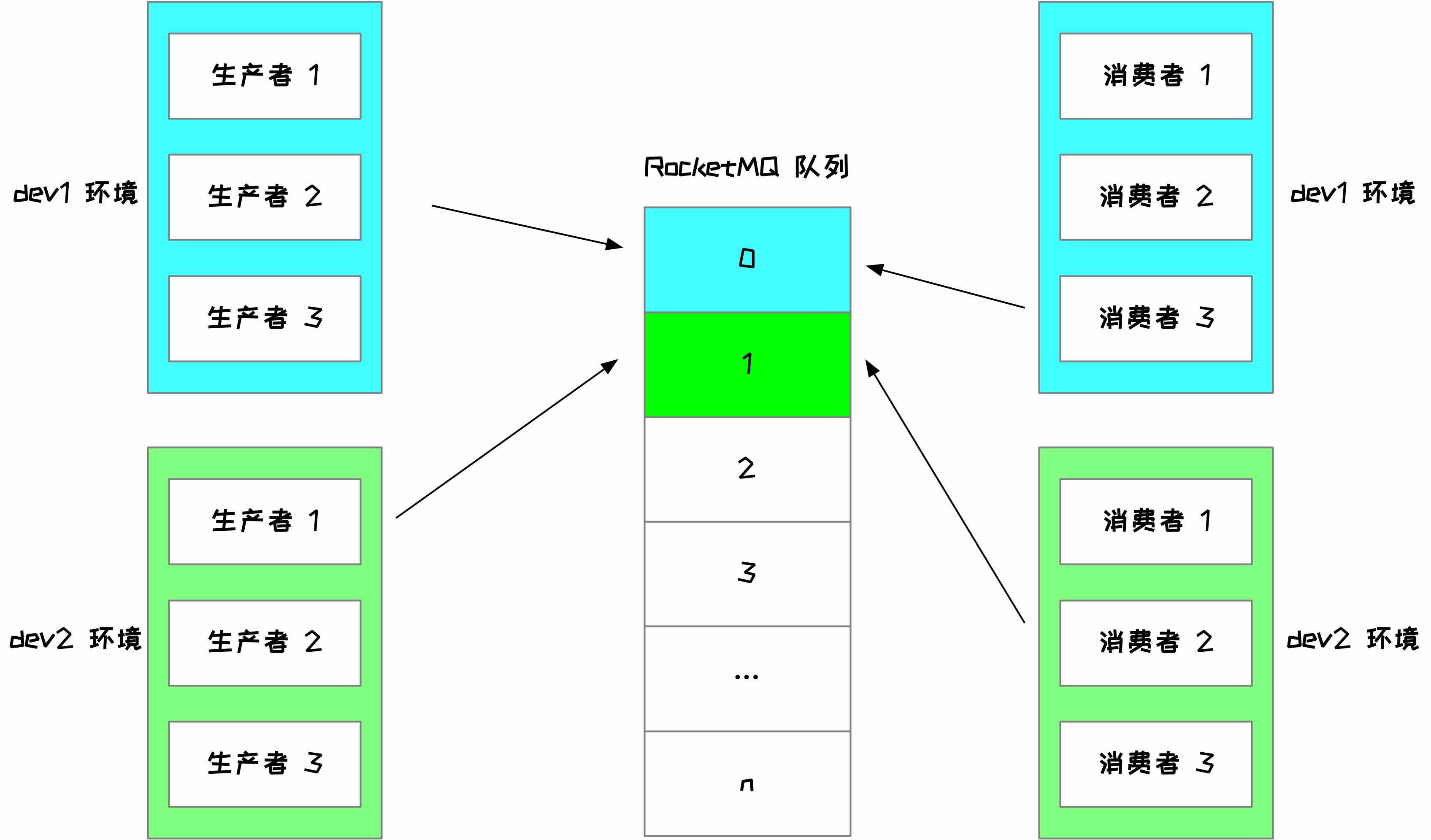
通过环境变量的区分
在生产端:dev1 环境投递到 RocketMQ 第 0 号队列,dev2 环境投递到第 1 号队列,后面以此类推
在消费端:dev1 环境只拉取 RocketMQ 第 0 号队列的消息,dev2 环境只第 1 号队列的消息,后面以此类推
生产端实现
RocketMQ 的消息投递提供了 MessageQueueSelector 接口可以自定义消息队列选择器,指定消息要投递的 queue,它的定义如下所示
public interface MessageQueueSelector {
MessageQueue select(final List<MessageQueue> mqs, final Message msg, final Object arg);
}
其中 mqs 参数是当前 topic 的所有可用队列,返回值是此次要投递的 queue。它有下面这个几个实现类:
SelectMessageQueueByHash:使用 msg 参数的 hashcode 的绝对值与 queue 大小取模
SelectMessageQueueByRandom:调用 Random.nextInt 方法获取一个 0~mqs.size()-1 区间的随机数
SelectMessageQueueByMachineRoom:实现为空
对于我们的场景,这里简化处理,根据环境的编号直接映射 queue,生产端的示例代码如下所示
DefaultMQProducer producer = // ...;
final int envIndex = getEnvIndex();
SendResult sendResult = producer.send(message, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
return mqs.get(envIndex-1);
}
}, envIndex);
这样 dev1 环境映射到第 0 个队列,dev3 环境映射到第 2 个队列。
消费端实现
对于消费端,RocketMQ 定义了 AllocateMessageQueueStrategy 策略接口,可以自己实现当前消费者可以消费哪些 queue 队列。AllocateMessageQueueStrategy 接口的定义如下所示
public interface AllocateMessageQueueStrategy {
/**
* Allocating by consumer id
*
* @param consumerGroup 当前 consumer group
* @param currentCID 当前 consumer id
* @param mqAll 当前 topic 的所有 queue 列表
* @param cidAll 当前 consumer group 下所有的 consumer id set 集合
* @return 根据策略给当前 consumer 分配的 queue 列表
*/
List<MessageQueue> allocate(
final String consumerGroup,
final String currentCID,
final List<MessageQueue> mqAll,
final List<String> cidAll
);
/**
* 策略算法名
*/
String getName();
}
RocketMQ 内置提供了下面这些分配算法
- AllocateMessageQueueAveragely:平均分配算法
- AllocateMessageQueueAveragelyByCircle:按照 queue 队列组成的环形逐个分配
- AllocateMachineRoomNearby:基于机房临近原则算法
- AllocateMessageQueueByMachineRoom:基于机房分配算法
- AllocateMessageQueueConsistentHash:基于一致性 hash 算法,将 consumer 消费者作为 Node 节点 hash 到一个虚拟环上
- AllocateMessageQueueByConfig:基于配置分配算法,没有什么作用,可以作为 example 扩展
对于我们的场景,这里简化处理,根据环境的编号直接映射 queue,消费端的代码如下所示
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(MQConstant.MQ_CONSUMER_GROUP_NAME, null,
new AllocateMessageQueueStrategy() {
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll, List<String> cidAll) {
List<MessageQueue> list = new ArrayList<>();
list.add(mqAll.get(envIndex-1));
return list;
}
@Override
public String getName() {
return "env-based";
}
});
利弊分析
这种方式的实现非常简单,客户端改动量非常小,不用修改 topic。如果你的环境数量比较固定,可以修改上面的策略,让一个环境可以使用固定的多个 queue,只要保证多个环境不使用同一个 queue 接口即可。如果开发测试环境的消息数量不多,用一个队列也问题不大。线上生产环境多机房、多环境也可以用类似的思路去实现。
到这里多环境隔离的介绍就告一段落。
消息丢失之伤
RocketMQ 本身是一个服务端,当然就会有服务不可用、服务繁忙等问题,尤其是我们的公司所有的业务共用一个 RocketMQ,时不时会出现 “system busy , start flow control for a while” 等投递异常问题。
为了解决投递可靠性的问题,一开始是想在投递异常的时候将消息写入到数据库等持久化存储中,然后有一个定时任务去补偿消费。这种方案看起来是比较完美的,但是当 RocketMQ 整体不可用,大量的消息都投递失败时,数据库的瞬间写入压力会非常大,这种方案没有被采用。
后面想到了使用 RocksDB 来曲线救国
主角 RocksDB
RocksDB 是 Facebook 基于 Google Jeff Dean 写的 LevelDB 改进的一种嵌入式 key-value 存储系统,做了许多优化,性能相对 LevelDB 有了很大的提升,大名鼎鼎的 TiDB 底层的存储引擎就是使用的 RocksDB。
RocksDB 是一个基于 LSM 树的存储引擎,LSM 是 Log-structured merge-tree 的缩写,关于 RocksDB 的底层原理,这篇文章不展开说明,有机会我会详细写一下。

基于 RocksDB 的重试机制
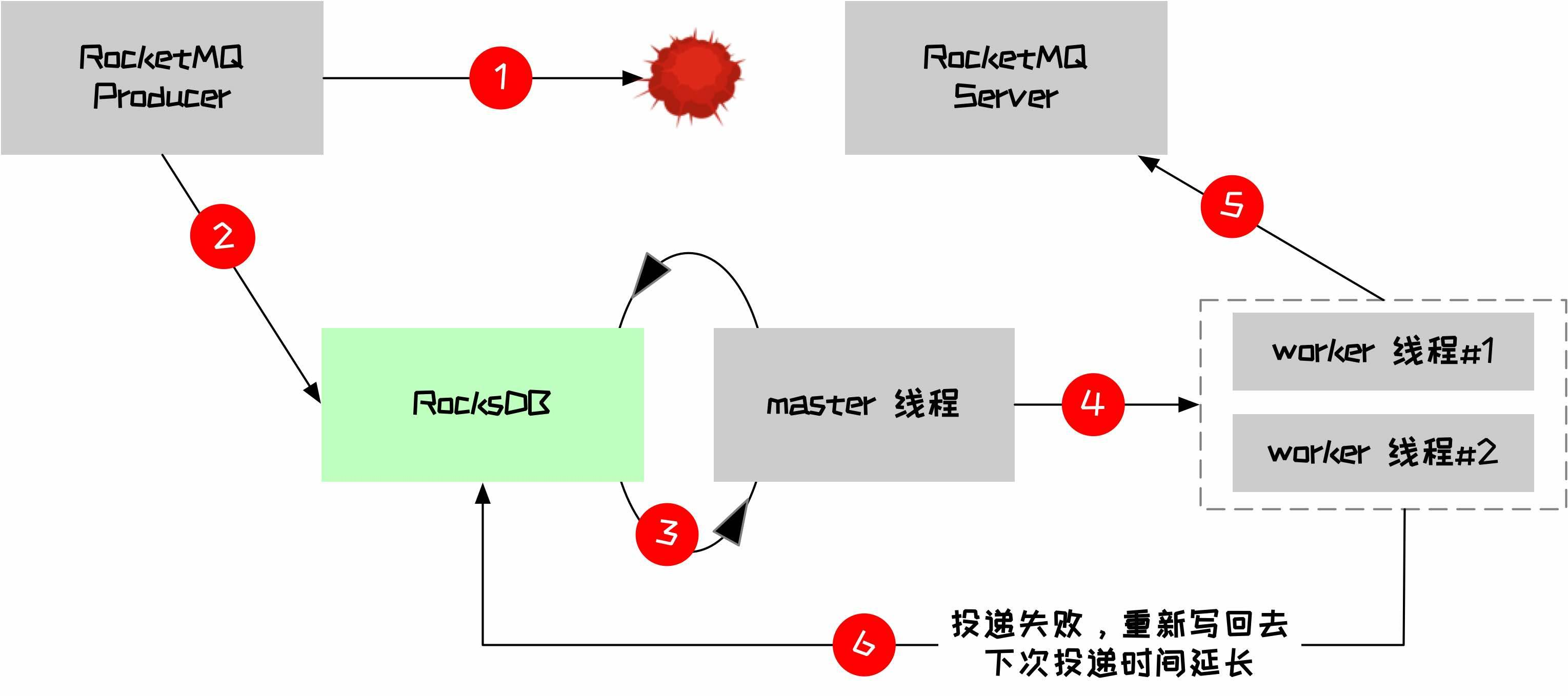
核心的逻辑是投递失败以后,将消息写入到本地 RocksDB 存储中,然后有一个线程去轮询是否有消息,如果有则进行重试,如果再次投递失败会重新将消息写入到 RocksDB,过程如下图所示
在实现上,写入 RocksDB 的 key 采用了如下的格式:
expireTime:retryCount:typeName:uuid
其中 expireTime 的生成逻辑为当前时间戳(到秒)+ 投递延迟时间,代码如下所示:
val RETRY_TIME_STEP_ARRAY = arrayOf(
3, 5, 30, 60, 120, 300, 480, 600, 900, 1800
)
val expire = System.currentTimeMillis() / 1000 + (RETRY_TIME_STEP_ARRAY.getOrNull(retryCount) ?: 10)
当消息投递到 MQ 失败时,将其写入到 RocksDB,这部分代码如下所示
private fun insert(msg: ByteArray, retryCount: Int, typeName: String) {
val key = genKey(retryCount, typeName)
rocksDB.put(mqRetryCFHandler, WRITE_OPTIONS_SYNC, key.toByteArray(), msg)
}
master 线程负责轮询 RocksDB,如果有记录将其查出来放入一个 blockingQueue 中,master 线程核心逻辑如下所示
private var lastSeekTime: Long = 0 // 单调递增的值,初始值为当前时间戳(到秒)
private fun loop() {
val now = // 当前时间戳,到秒
if (lastSeekTime > now) { // 如果时钟回拨或者还没到处理时间片,睡眠一段时间
TimeUnit.MILLISECONDS.sleep(400)
return
}
rocksDB.newIterator(mqRetryCFHandler, READ_OPTIONS).use {
it.seek("$lastSeekTime".toByteArray()) // seek 到以 lastSeekTime 开头的 key 的地方
while (it.isValid) {
val value = it.value()
blockingQueue.put(String(it.key()) to value) // 放入一个固定大小的阻塞队列中
it.next()
}
}
++lastSeekTime
}
worker 线程负责消息的重新投递,代码如下所示
private fun startConsume() {
repeat(THREAD_NUM) {
thread {
while (true) {
val list = drain() // 批量从 blockingQueue 中取数据
list.forEach {
try {
val typeName = getTypeName(it.first)
val handler = getHandler(typeName) ?: return@forEach
val success = handler.handler(it.second)
// 如果不成功,则重新写入 RocksDB
if (!success) {
val currentRetryCount = getRetryCountFromKey(it.first) + 1
val maxRetryCount = handler.retryCount
if (currentRetryCount >= RETRY_TIME_STEP_ARRAY_SIZE || currentRetryCount >= maxRetryCount) {
val msgString = getStringFromBytes(it.second)
logger.info("send reach limit, retry count:$currentRetryCount,default count:$RETRY_TIME_STEP_ARRAY_SIZE,custom count:$maxRetryCount, msg: $msgString")
exceptionHandle.handler("retry $currentRetryCount fail,msg:$msgString")
return@forEach
}
insert(it.second, currentRetryCount, typeName)
}
} catch (ex: Throwable) {
exceptionHandle.handler("key: $it.first ,error: ${ex.message}")
Thread.sleep(30)
}
}
}
}
}
}
通过上面的这几步改造,在过去大半年内成功的躲过了好几次 RocketMQ 的短时间故障,消息没有丢失,全部重试成功,没有造成数据的异常。
利弊分析
这个方案的优点是很轻量化,写入读取本地 RocksDB 速度都极快,在极端场景下性能几乎没有影响。但也有一个缺点需要考虑,因为没有落地到集中式存储比如 MySQL,如果项目部署到 Docker 容器中,容器重启以后,这部分重试的数据还是会丢失。使用这种方案没有办法保证百分百不丢数据,考虑到 mq 故障发生的并不频繁,在性能和丢数据中取得一个平衡也是一种可行的措施。
基于 RocksDB 的任意延时消息设计
在做完上面的“可靠投递”方案以后,衍生出另外一个解决方案,使用 RocksDB 来实现任意时延的延时消息队列,它的设计目标有三个:
支持任意时延
充分利用现有的基础设施
需要能无限堆积,写入查询效率要求要高
于是基于 RocksDB,我们实现了一个内部称为 Rock-DMQ 的项目,名字来源是 RocksDB for Delay MQ。它的实现原理也非常简单,如下图所示。
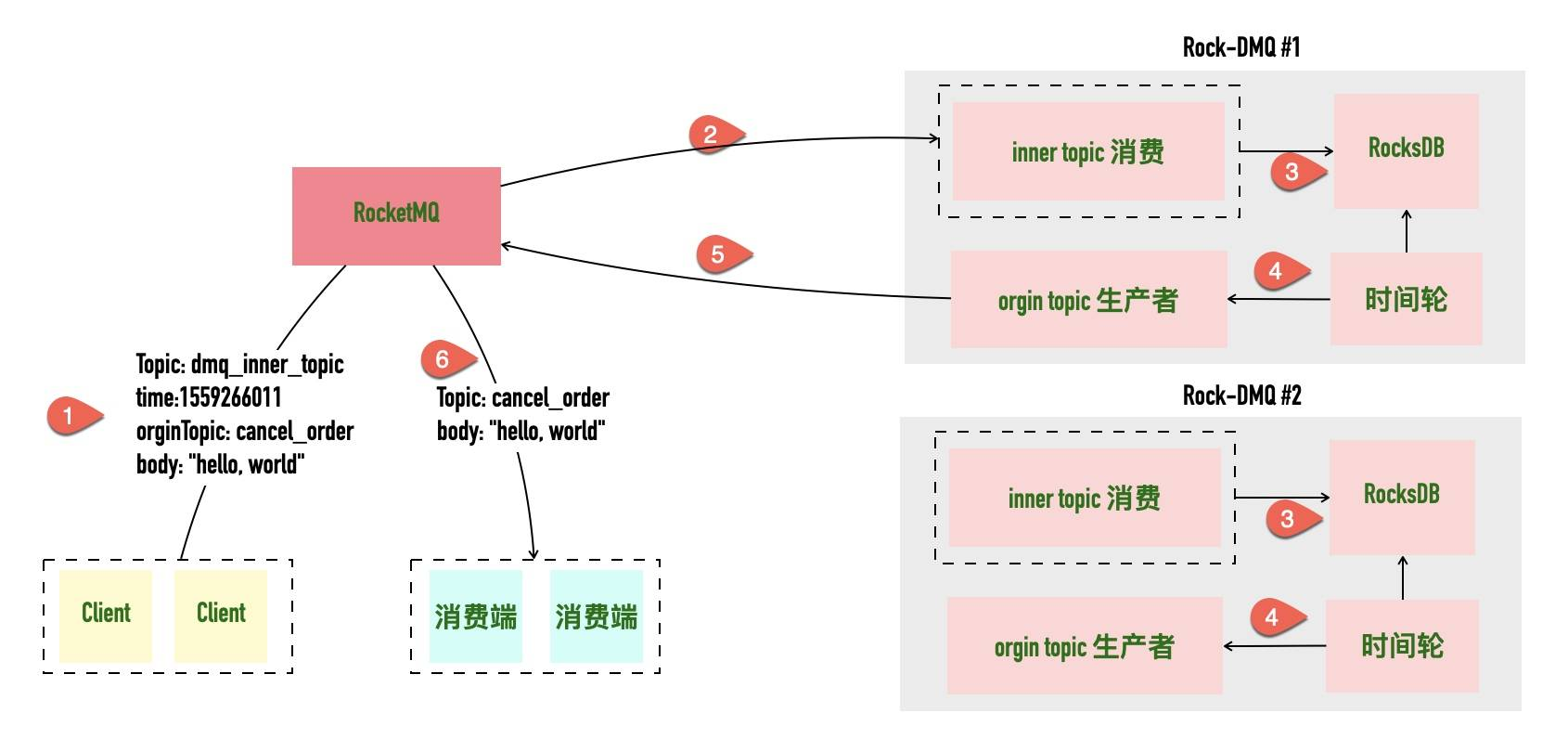
在投递一个延时消息时,以 topic 为 “cancel_order” 为例,整个延时消息的实现逻辑如下所示。
1、通过修改 Producer 端,实际投递到 RocketMQ 的 topic 不是这个,而是替换为了一个统一的 topic,名为 dmq_inner_topic,原始 topic 被转为 body 的一部分。
2、Rock-DMQ 项目会消费 dmq_inner_topic 这个特殊的 topic
3、消费 dmq_inner_topic 的消息后,Rock-DMQ 项目会将其写入到本地的 RocksDB 中,key 为到期时间为前缀(这一点比较重要)
4、Rock-DMQ 项目采用文中第二部分的内容相似的实现方式,隔一段时间去轮询 RocksDB ,看有无到期的消息
5、如果有到期消息,Rock-DMQ 项目将这个消息投递到 RocketMQ 中
6、订阅了这个 topic 的原有消费端就可以消费到这条消息了
通过这种实现,可以实现支持任意秒数的时延消息,也比较好的复用了现有的技术组件,对 RocketMQ 本身无任何改动,在水平扩展性上也得到了比较好的支持。
核心代码在第二部分已经介绍,这里不再赘述。
小结
以上就是 RocketMQ 在我们这边的落地实践和填坑记录,这些方案都还在快速迭代优化中,如果你有更好的想法,可以一起沟通交流~


