
Redis进阶:深入解读阿里云Redis开发规范(修订版)原创
Key命名设计:可读性、可管理性、简介性
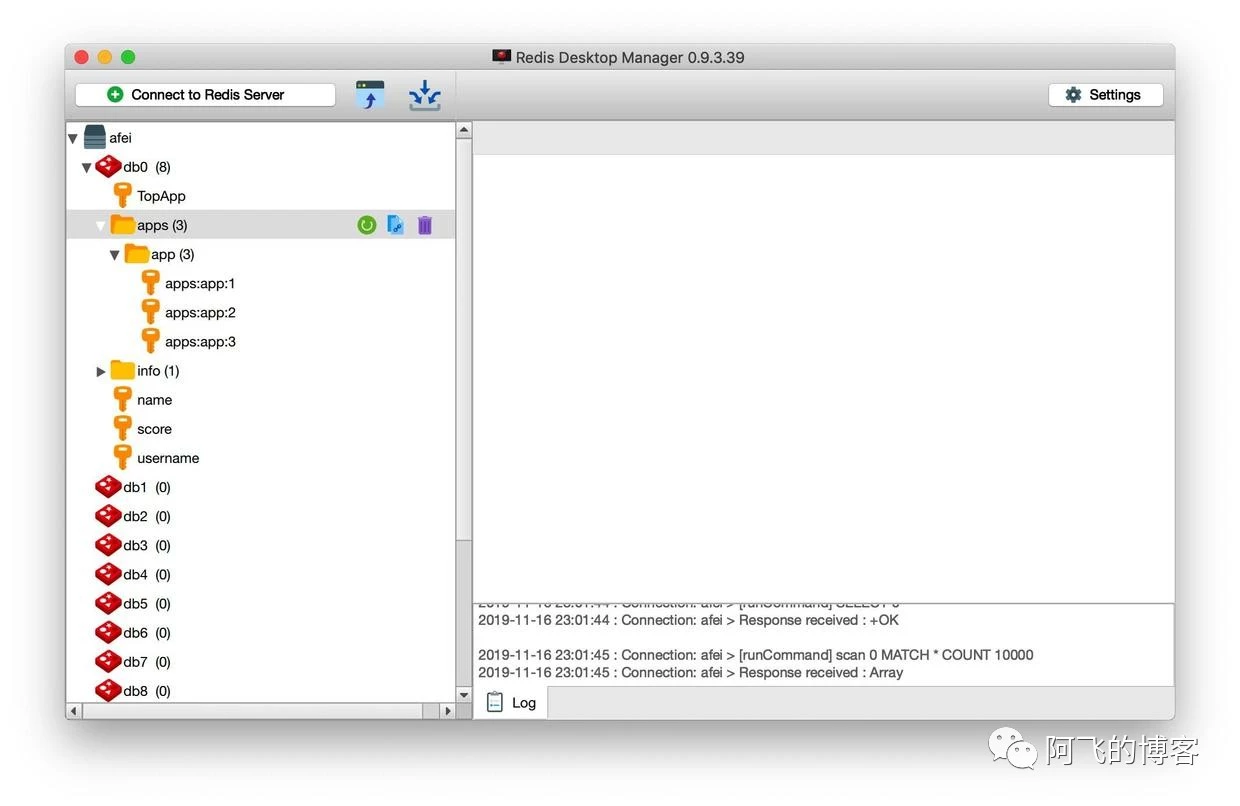
规范建议使用冒号即:进行分割拼接,因为很多Redis客户端是根据冒号分类的。比如有几个Key:apps:app:1、apps:app:2和apps:app:3。Redis Desktop Manager能自动归类到apps目录下。如下图所示:
Value设计:拒绝bigkey
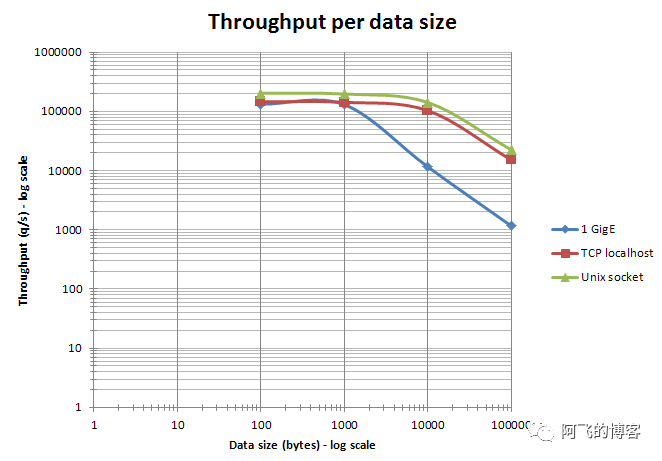
规范建议String类型的Value控制在10KB范围以内。这是因为Redis随着Value不断增长,在超过10KB后,有一个非常奇妙的性能拐点,如下图所示(图片来自Redis官网:http://redis.cn/topics/benchmarks.html):
假设内网带宽是千兆网卡,即1000MB。假设你的Redis中有一个大Key的Value长度是10KB,并且这个Key的QPS是10W,那么这一个Key就会把带宽打满:10KB*100000=1000MB。
控制Key的生命周期:设定过期时间
尽可能对每一个Key都设置过期时间,这个是非常有益处的。否则,你想象一下,半年以后,一年以后,你的Redis集群中有上百G甚至更多的数据,谁都不知道这些数据哪些是有价值的,哪些已经成为垃圾。如果你的每个Key都设置了过期时间,那么就不会出现这个问题了。集群在运行过程中,或自动淘汰那些已经不再使用的垃圾缓存数据。
时间复杂度为O(n)的命令需要注意N的数量
这个建议的意思是,以List类型为例,LINDEX、LREM等命令的时间复杂度就是O(n)。也就是说,随着List中元素数量越来越多,这些命令的性能越来越差。而Redis又是单线程的,如果出现一个慢命令,会导致在这个命令之后执行的命令耗时也会增长,这是使用Redis的大忌。
事实上这也是JDK8为什么要对HashMap进行链条冲突优化:当entry数量不少于64时,如果冲突链表长度达到8,就会将其转成红黑树。因为链表长度越长,性能会越来越差。
禁用命令:KEYS、FLUSHDB、FLUSHALL等
这些命令应该在搭建Redis环境的时候就要禁用掉(在config配置文件中通过rename-command禁用)。FLUSHDB和FLUSHALL这两个命令会清空数据,后果可想而知。
至于KEYS命令,还记得那个由于使用这个命令导致几百万损失的案例嘛?而且,这个命令的不当使用导致的损失,会随着你的业务并发越大价值越大而导致损失越大:

合理使用select
select的作用是选择redis的db,这是只有在非cluster模式下才能起作用的。默认db数量为16,可以通过redis.conf中的databases进行配置。
阿里云Redis规范建议谨慎多个业务运行在同一个Redis实例的多个db上。这是因为redis整个实例是单线程处理命令的,这就意味着,如果某个db上有慢命令,那么会影响其他db上的实例。当然,Redis6.0准备支持多线程,但是还是不建议这样做!
不推荐使用事务
如果你有使用关系式数据库的经验,那么“Redis在事务失败时不进行回滚,而是继续执行余下的命令”这种做法可能会让你觉得有点奇怪。以下是官方给出的Redis不支持这种做法的优点:
- Redis命令只会因为错误的语法而失败,或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
删除bigkey
如果Redis中有大key,那么删除可能会产生毛刺。当然,如果你的Redis是4.0以上,并使用UNLINK命令删除key,那么不会有什么问题。那Redis4.0以下该怎么删除大key呢?
如果是hash结构,那么先利用scan命令遍历得到一批field,然后利用hdel命令进行删除;如果是list结构,那么先利用llen得到list中元素总个数,然后利用ltrim命令批量删除;
如果是set结构,那么先利用sscan命令遍历得到一批key,然后利用srem命令批量删除;如果是sorted set结构,那么先利用zscan命令遍历得到一批key,然后利用zrem命令批量删除;如果是string结构呢?没有什么很好的办法!
设置合理的内存淘汰策略
Redis的内存剔除策略(maxmemory-policy)有:volatile-lru、volatile-random、volatile-ttl、allkeys-lru、allkeys-random、noeviction。命名以volatile开头的3个策略主要作用于带有失效时间属性的key,命名以allkeys开头的2个策略作用于所有key,最后一个策略noeviction不会剔除任何数据,只是当内存使用满了以后拒绝所有写入操作并返回客户端错误信息"(error) OOM command not allowed when used memory",此时Redis只响应读操作。
事实上每种方案都有一定的局限性,所以我们除了根据自己的业务选择合适的剔除策略以后,还需要对Redis使用的内存进行监控,主要监控info中info Memory段的used_memory_peak,即Redis使用内存峰值,建议设置其告警阈值为maxmemory的90%。
使用批量操作提升操作效率
批量命令主要分为两类,原生命令和非原生命令:
- 原生命令包括:例如mget、mset、hmget、hmset、LPUSH key value集合等。
- 非原生命令包括:Pipeline。
合理使用这些命令对操作性能提升是极其巨大的,尤其在单机Redis或者Sentinel模式下。因为这两种架构不涉及跨Slot,Redis集群性能也有提升,但是使用会受到一些限制,例如不支持跨Slot的操作等,官方并不太建议在Rdis集群环境下使用Pileline和multi key操作。
当然批量虽好,但不要贪多。俗话说的好,贪多嚼不烂。一般不要超过1000,具体限制还与操作数据大小有关。
monitor命令控制使用时间
monitor命令一般是用来观察redis服务端都在执行哪些命令并实时输出。例如在其他redis-cli中执行两个set命令,在monitor中监控结果如下:
afeiMacBook-Pro:redis-3.2.11 afei$ src/redis-cli monitor
OK
1573915193.053188 [0 127.0.0.1:55357] "COMMAND"
1573915197.087383 [0 127.0.0.1:55357] "set" "name" "afei"
1573915217.938838 [0 127.0.0.1:55357] "set" "公众号" "阿飞的博客"之所以规范建议控制monitor命令的使用时间,是因为随着monitor命令执行时间越来越长,会导致越来越多的数据积压在输出缓冲区,从而导致输出缓冲区占用内存越来越大。而且,这种影响会由于Redis并发越高,而更加放大。关于这个问题,美团有一个很经典的案例,感兴趣的同学可以搜索关键词:“美团在REDIS上踩过的一些坑-3.REDIS内存占用飙升”。
写在最后
总而言之,任何一门技术都有利有弊,技术的世界里没有银弹。所以,我们对使用到生产环境的任何一个技术,都要非常熟悉:知道它所擅长的和它的弱点,这样才能结合自己的项目特点,设计出更合理的架构,编写出最合理的代码,不给生产环境造成影响,不给公司带来损失 – 千万不要成为那个执行KEYS命令导致给公司造成金钱损失的人!


