
CPU上下文切换导致服务雪崩原创
5年前
1120937
事故描述
某线上web服务流量突增,导致整个应用雪崩。雪崩期间,线上服务器登录困难,只能联系运维人员,在nginx层拒绝部分流量之后,重启服务问题才能得以解决。
故障查找过程
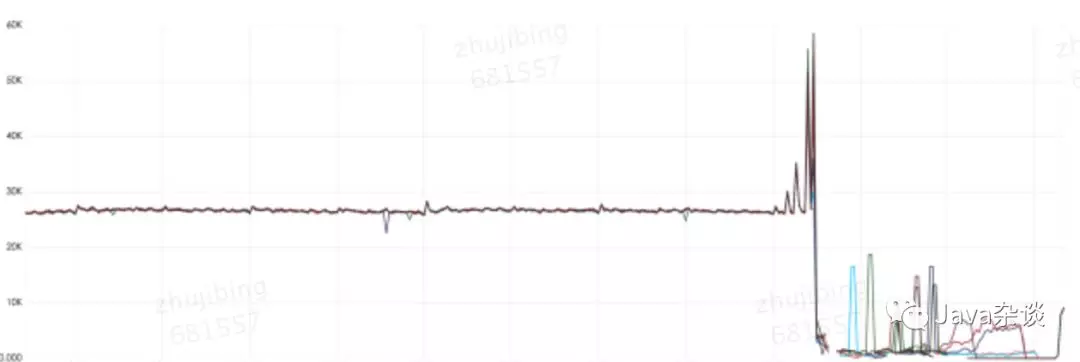
首先,发现流量突增,并且呈现四波峰值,最后一波导致服务彻底挂掉。
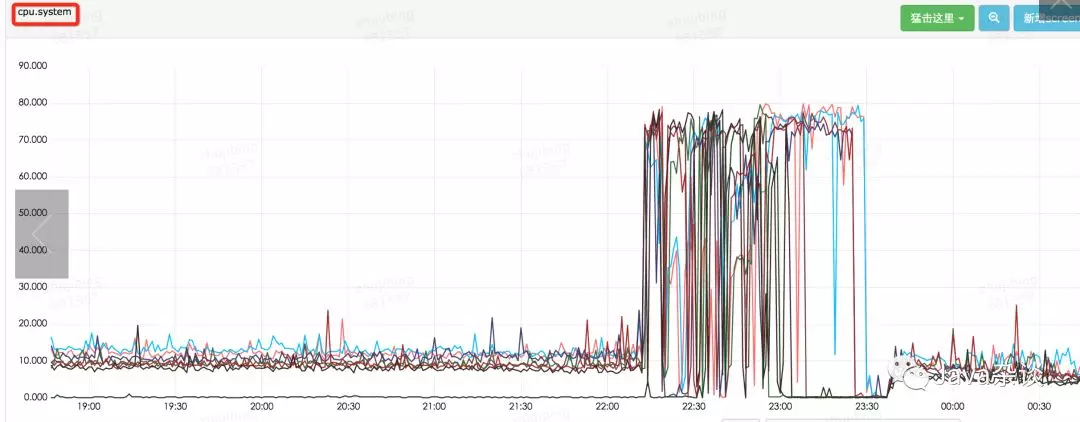
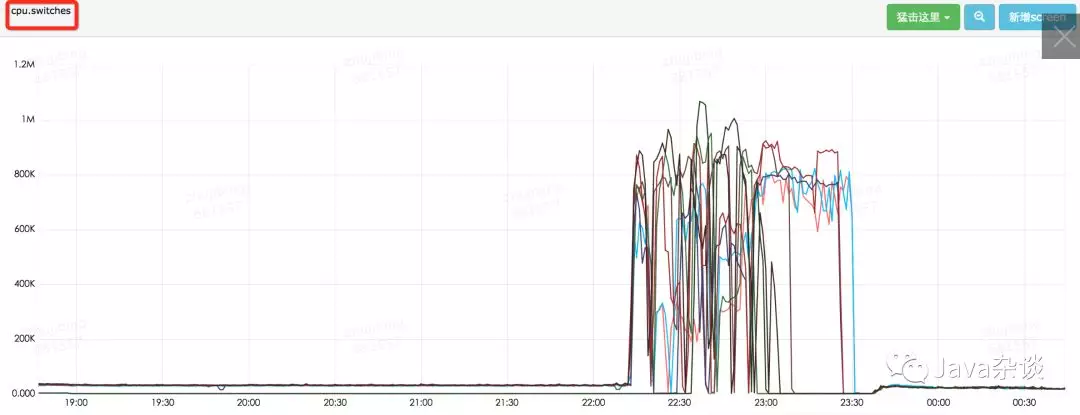
然后、发现机器cpu利用率特别高,基本上都是系统态时间;并且发生了大量的cpu切换(在故障时间,每台机器cpu切换次数在1百万左右)。
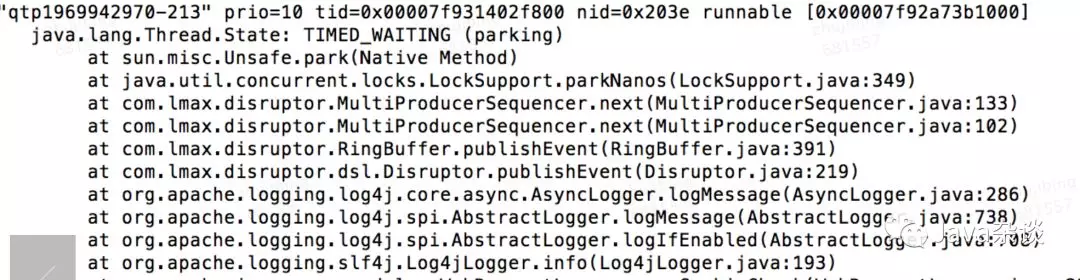
最后、检查线程栈,发现大部分Jetty线程都卡在了Unsafe.park上。
故障原因分析
结合线程栈和相关代码可以发现:在log4j使用异步AsyncLogger写日志导致。AsyncLogger使用了disruptor框架,而disruptor框架在核心数据结构RingBuffer上处理MultiProducer。在写入日志的时候需要Sequence,但是此时RingBuffer已经满了,获取不到Sequence,disruptor会调用Unsafe.park会将当前线程主动挂起。简单来说就是消费速度跟不上生产速度的时候,生产线程做了无限重试,重试间隔为1 nano,导致cpu频繁挂起唤醒,发生大量cpu切换,占用cpu资源。
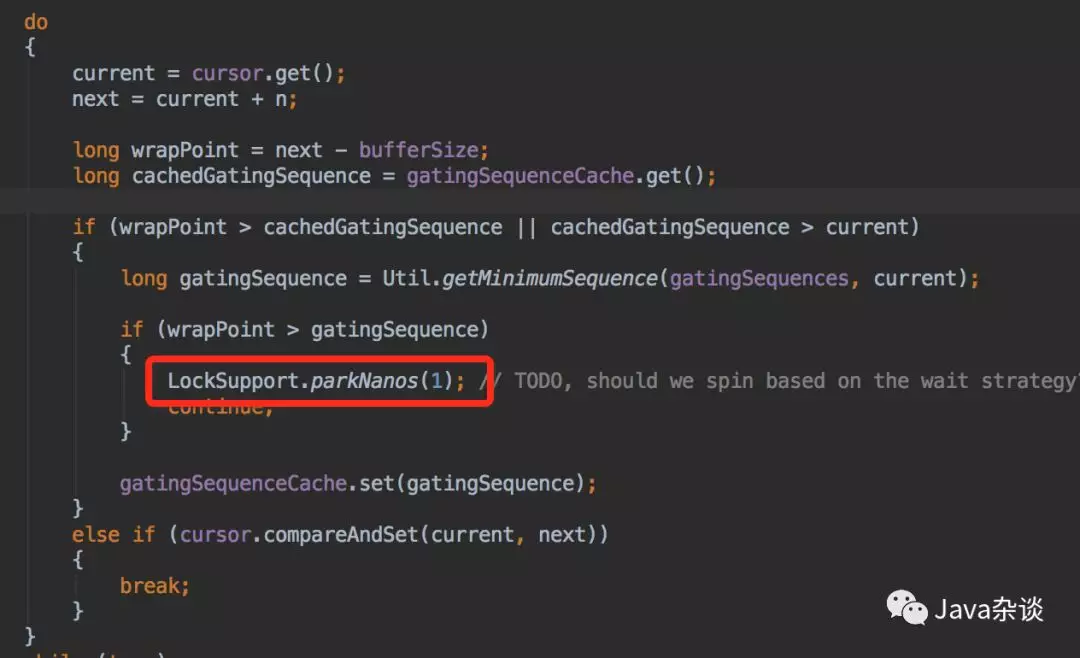
问题解决
该问题属于log4j/disruptor框架层面的bug,并且在2016.8月就有人发现在问题,并且在当年10月份就修复了,所以把Distuptor版本和og4j2版本,分别到3.3.6 和 2.7问题就得以解决。
写在最后
cpu切换会消耗大量的cpu资源,并且给出了测试cpu切换消耗资源的基准测试方法。本文给出的例子在每秒发生1百万次的cpu切换服务基本上就不可用了,和上篇文章基准测试的值基本一致。
点赞收藏
分类:

