
MySQL之KEY分区引发的血案原创
需求背景
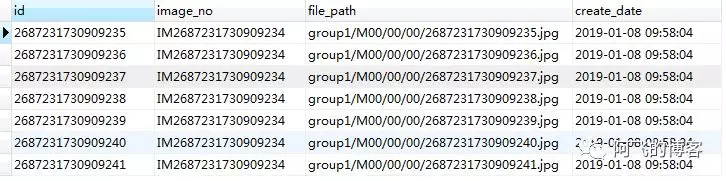
业务表tb_image部分数据如下所示,其中id唯一,image_no不唯一。image_no表示每个文件的编号,每个文件在业务系统中会生成若干个文件,每个文件的唯一ID就是字段id:
业务表tb_image的一些情况如下:
- 根据image_no查询和根据id查询;
- 存量数据2kw;
- 日增长4w左右;
- 日查询量20w左右;
- 非ToC系统,所以并发的天花板可见;
方案选择
根据上面对业务的分析,分库分表完全没有必要。单库分表的话,由于要根据image_no和id查询,所以,一种方案是冗余分表(即一份数据以image_no为分片键保存,另一份数据以id为分片键保存);另一种方案是只以image_no为分片键,而基于id的查询需求,业务层进行结果归并或者引入第三方中间件。
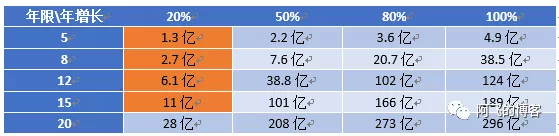
考虑到单库分表比较复杂,所以决定使用分区特性,而且容量评估分区表方案128个分区(每个分区数据量kw级别)完全能保证业务至少稳定运行15年(图中橙色部分是比较贴合自身业务实际增长情况):
另外,由于RANGE, LIST, HASH分区都不支持VARCHAR列,所以决定采用KEY分区,官方介绍它的原理是以MySQL内置hash算法然后对分区数取模。
性能测试
选定分片键为image_no,并且决定分区数为128后,就要灌入数据进行可行性和性能测试了。分区数选择128的原因是:11亿/1kw=110≈128,另外程序员情节,喜欢用2的N次方,你懂的。然而,这个分区数128就是一切噩梦的开始。
我尝试先插入10w数据到128个分区中,插入后,让我惊讶的现象出现了:所有奇数编号分区(p1, p3, p5, … , p2n-1)中居然没有一条数据,同时,任何一个偶数编号分区却有很多的数据,而且还不是很均匀。如下图所示:
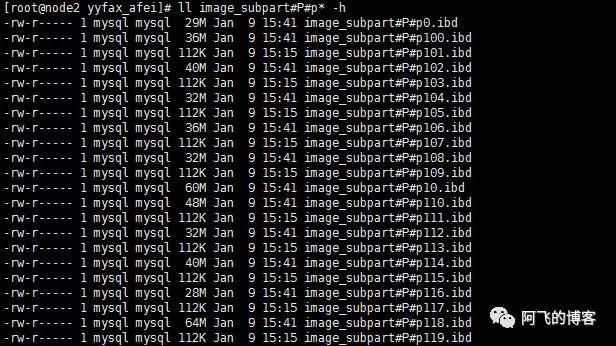
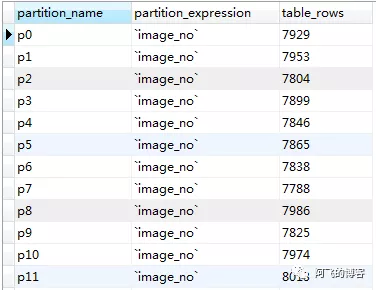
说明:奇数编号分区的ibd文件大小都是112k,这是创建分区表时初始化大小,实际并没有任何数据。我们可以通过SQL:select partition_name, partition_expression, table_rows from information_schema.partitions where table_schema = schema() and table_name='image_subpart';验证,其部分结果如下图所示:
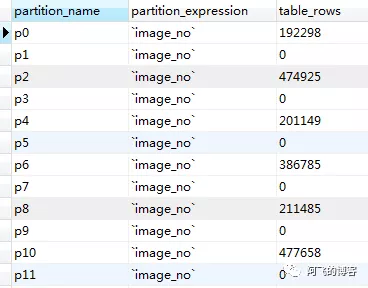
难道10w条数据还不够说明问题?平均下来每个分区可是有近800条数据!好吧,来点猛的:我再插入990w条数据,总计1kw数据。结果还是一样,奇数编号分区没有数据,偶数编号都有分区。
问题思考
我们再来回想一下KEY分区的原理:通过MySQL内置hash算法对分片键计算hash值后再对分区数取模。这个原理也可以从MySQL官网找到,请戳链接:22.2.5 KEY Partitioning: https://dev.mysql.com/doc/refman/5.7/en/partitioning-key.html,截取原文如下:
Partitioning by key is similar to partitioning by hash, except that where hash partitioning employs a user-defined expression, the hashing function for key partitioning is supplied by the MySQL server. NDB Cluster uses MD5() for this purpose; for tables using other storage engines, the server employs its own internal hashing function which is based on the same algorithm as PASSWORD().
**这个世界上不会有这么渣渣的hash算法吧?**随便写个什么算法也不至于这么不均匀吧?这时候我怀疑是否有一些什么配置引起的。但是show variables中并没有任何与partition相关的变量。
这个时候,一万匹马奔腾而过。会不会是文档和源码不同步导致的?好吧,看MySQL的源码,毕竟,源码才是最接近真相的地方。KEY分区相关源码在文件sql_partition.cc中,笔者截取部分关键源码,如下所示,初略观察,并没有什么不妥,先计算分区字段的hash值然后对分区数取模:
/**
Calculate part_id for (SUB)PARTITION BY KEY
@param file Handler to storage engine
@param field_array Array of fields for PARTTION KEY
@param num_parts Number of KEY partitions
@param func_value[out] Returns calculated hash value
@return Calculated partition id
*/
inline
static uint32 get_part_id_key(handler *file,
Field **field_array,
uint num_parts,
longlong *func_value)
{
DBUG_ENTER("get_part_id_key");
// 计算分区字段的hash值
*func_value= file->calculate_key_hash_value(field_array);
// 对分区数取模
DBUG_RETURN((uint32) (*func_value % num_parts));
}
怀着绝望的心情,请出搜索引擎搜索:“KEY分区数据不均匀”,搜索结果中的CSDN论坛(https://bbs.csdn.net/topics/390857704)里有个民间高手华夏小卒回答如下:
一个同事根据password函数,分析并测出,key分区,只能指定分区数目为质数,才能保证每个分区都有数据。我测了下,从11个分区,到17个分区。 只有11,13,17 ,这3个分区的数据是基本平均分布的。
这个时候,又是一万匹马奔腾而过。不过 WHAT THE F**K 的同时,心里也是有点小激动,因为可能找到解决办法了(虽然还不知道MySQL内置hash算法为毛会这样),最后笔者再次对KEY分区测试并得出总结如下:
-
如果设置40,64,128等偶数个分区数(PARTITIONS 64),会导致编号为奇数的分区(p1, p3, p5, p7, … p2n-1)完全插不进数据;
-
如果设置63,121(PARTITIONS 63)这种奇数但非质数个分区数,所有分区都会有数据,但是不均匀;
-
如果设置137,31这种质数个分区数(PARTITIONS 137),所有分区都会有数据,并且非常均匀;
如下图所示,是笔者把分区数调整为127并插入100w数据后的情况,通过SQL证明每个分区的数据量几乎一样:
总结回顾
MySQL的KEY分区这么大的使用陷阱,居然在官方上没有任何说明,这让笔者感到非常震惊。此外还有MySQL bug:Bug #72428 Partition by KEY() results in uneven data distribution
正在看此文并有很强烈兴趣的同学,可以尝试更深入这个问题。笔者接下来也会找个时间,根据MySQL源码深入挖掘其hash算法的实现为什么对分区数如此敏感。


