
一次“内存泄漏”引发的血案原创
对性能不佳的Ark Server进行了改造和重写。重编发布一段时间后,结果发现新发布的Svr的机器内存一直在上涨。如下图示:
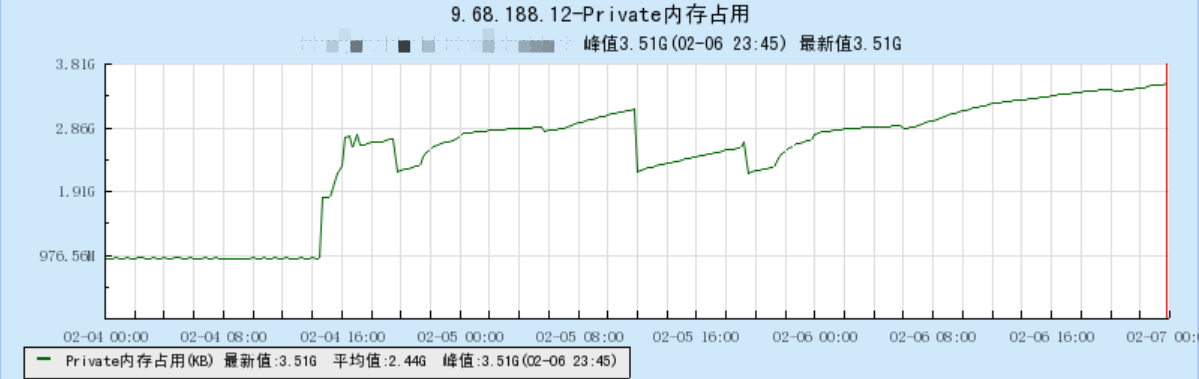
观察后,第一反应是完了,一定存在内存泄露。花了3、4天时间,使用各种办法进行定位,一无所获。
后来无意中在SPP日志中发现了端倪,日志中一直打印tcp socket[%d] user check pkg not ok, but no more memory,看代码逻辑,是收包缓冲区太小,导致调用方不断使用new操作来扩充缓冲区,我仔细检查了下调用方的代码逻辑,使用的是SPP微线程架构,收包缓冲区是一个Msg的局部变量,在Msg析构时,都会调用delete,换而言之,这里绝不可能存在内存泄露。
既然不存在内存泄露,内存为什么会一直涨呢?按照
上图来看,内存在1天内涨了1G左右,这个速度也太可怕了吧。既然唯一的线索在内存分配操作new和delete上,那么只可能是这里有猫腻。
网上搜索了下delete not return memory,果然说来话长啊。下面我们就来回顾下C++程序中的内存管理机制
物理内存、虚拟内存
物理内存好说,就是机器的真实内存,你机器是多大内存条,物理内存就多大。虚拟内存(虚拟地址空间)是一个逻辑概念,32bit下每个进程都有4G虚拟地址空间,而且每个进程间的地址空间相互独立。
从进程的角度来说,每个进程均认为自己独享整个内存空间(4G)。进程空间分布如下图:
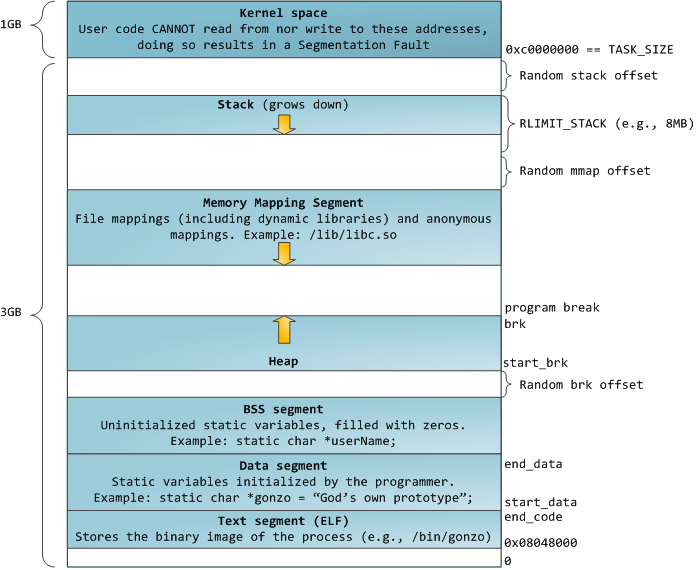
如上图示:最高的1G空间保留给内核使用。接下来是栈,栈向低地址方向延伸(栈的大小受RLIMIT_STACK限制,默认为8M),下面是MMAP区(文件映射内存,如动态库等,SPP微线程的私有栈也位于这里)下面是堆(动态内存增长),堆向高地址方向延伸,接下来依次是BSS、数据段、代码段。
需要注意的一点是:上面所说的都是虚拟内存。只有在真正使用到这片内存空间时,才会涉及到物理内存页的分配等(内核管理,页错误)。
Linux下动态内存分配实现机制
C、C++的动态内存分配、管理都是基于malloc和free的,动态内存即虚拟空间堆区。另外多说一句,malloc和free操作的也是虚拟地址空间。
malloc,动态内存分配函数。是通过brk(sbrk)和mmap这两个系统调用实现的。
结合上文进程虚拟空间图,brk(sbrk)是将数据段(.data)的最高地址指针_edata往高地址推。mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。这两种实现方式的区别大致如下:
1.brk(sbrk),性能损耗少;mmap相对而言,性能损耗大
2.mmap不存在内存碎片(是物理页对齐的,整页映射和释放);brk(sbrk)可能存在内存碎片(由于new和delete的顺序不同,可能存在空洞,又称为碎片)
无论是通过brk(sbrk)还是mmap调用分配的内存都是虚拟空间的内存,只有在第一次访问已分配的虚拟地址空间的时候,发生缺页终端,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
delete,动态内存释放函数。如果是brk(sbrk)分配的内存,直接调用brk(sbrk)并传入负数,即可缩小Heap区的大小;如果是mmap分配的内存,调用munmap归还内存。无论这两种那种处理方式,都会立即缩减进程虚拟地址空间,并归还未使用的物理内存给操作系统。
brk(sbrk)和mmap都是系统调用,如果程序中频繁的进行内存的扩张和收缩,每次都直接调用,当然可以实现内存精确管理的目的,但是随之而来的性能损耗也很显著。目前大多数运行库(glibc)等对内存管理做了一层封装,避免每次直接调用系统调用影响性能。如此,就设计到运行库的内存分配的算法问题了。
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。
如何查看进程发生缺页终端的次数?
用ps -o majflt,minflt -C program命令查看。
majflt代表major fault,中文名叫大错误,minflt代表minor fault,中文名叫小错误。这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
发生缺页中断后,执行了哪些操作?
当一个进程发生缺页中断的时候,进程会陷入内核态,执行一下操作:
1、检察要访问的虚拟地址是否合法。
2、查找/分配一个物理页
3、填充物理页内容(读取磁盘,或者直接置0,或者啥也不干)
4、建立映射关系(虚拟地址到物理地址)
重新执行发生缺页终端的那条指令
如果第三步,需要读取磁盘,那么这次缺页中断就是majflt,否则就是minflt。
查看物理内存使用情况: cat /proc/$PID/smaps,里面详细记录了该进程使用的物理页内存情况,如Private_Dirty、Private_Clean等
mmap系统调用:读写MMAP映射区,相当于读写被映射的文件。本意是将文件当做内存一样读写。相比Read、Write,减少了内存拷贝(Read、Write一个硬盘文件,需要先将数据从内核缓冲区拷贝到应用缓冲区(read),然后再将数据从应用缓冲区拷贝回内核缓冲区(write)。mmap直接将数据从内核缓冲区映射拷贝到另一个内核缓冲区),但是被修改的数据从MMAP区同步到磁盘文件上,依赖于系统的页管理算法,默认hi慢条斯理的将内容写到磁盘上。另外提供了msync强制同步到磁盘上。
Glibc内存分配算法
glibc的内存分配算法,是基于dlmalloc实现的ptmalloc,dlmalloc详细可以参考A Memory Allocator或者我之前的文章Glibc内存分配器。这里主要讲下和内存归还策略相关的,其他内容不做过多扩展。
整体来说,glibc采用的是dlmalloc。为了避免频繁调用系统调用,它内部维护了一个内存池,方便reuse,又称为free-list或bins,如下图所示:
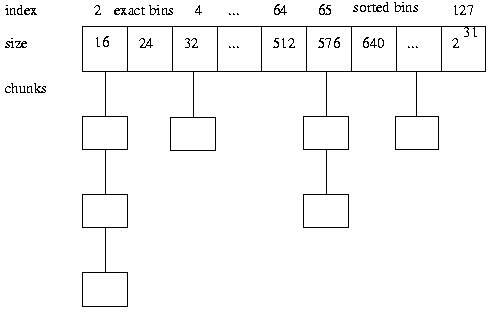
所有调用delete释放的内存,并不是立即调用brk(sbrk)归还给操作系统,而是先将这个内存块挂在free-list(bins)里面,然后进行内存归并(可选操作,相邻的可用内存块合并为更大的可用内存块),并检查是否达到malloc_trim的threshhold,如果达到了,则调用malloc_trim归还部分可用内存给操作系统。
glibc中,设置了默认进行malloc_trim的threshhold为128K,也就是说当dlmalloc管理的内存池中最大可用内存>128K时,就会执行malloc_trim操作,归还部分内存给操作系统;而在可用内存<=128K时,及时程序中delete了这部分内存,这些内存也是不归还给操作系统的。表现为:调用delete之后,进程占用的内存并没有减少。
另外,部分glibc的默认设置如下:
DEFAULT_MXFAST 64 (for 32bit), 128(for 64bit) //free-list(fastbin)最大内存块
DEFAULT_TRIM_THRESHOLD 128 * 1024 // malloc_trim的门槛值 128k
DEFAULT_TOP_PAD 0
DEFAULT_MMAP_THRESHOLD 128 * 1024 // 使用mmap分配内存的门槛值 128k
DEFAULT_MMAP_MAX 65536 // mmap的最大数量
这些参数都可以通过mallopt进行调整。
malloc_trim(0)可以立即执行trim操作,将内存还给操作系统。
具体fastbin相关的内容,此处不做介绍,前期有很多基于fastbin的堆溢出攻击,感兴趣的同学可以google关键字fastbin搜索下。
测试:
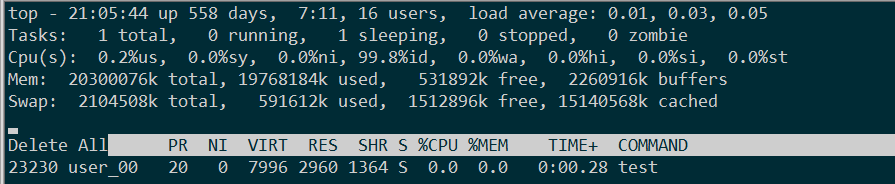
1.循环new分配64K * 2048的内存空间,写入脏数据后,循环调用delete释放。top看进程依然使用131M内存,没有释放。 ---- 此时用brk
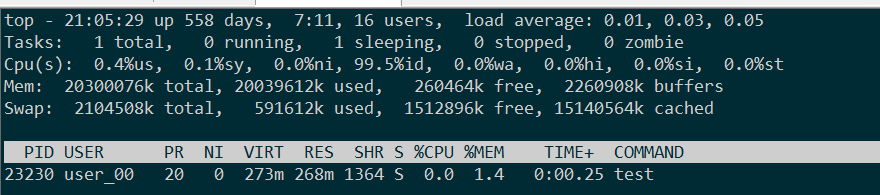
2.循环new分配128K * 2048的内存空间,写入脏数据后,循环调用delete释放。top看进程使用,2960字节内存,完全释放。 ----此时用mmap
3.设置M_MMAP_THRESHOLD 256k, 循环new分配128k * 2048的内存空间,写入脏数据后,循环调用delete释放,而后调用malloc_trim(0).top看进程使用,2348字节,完全释放。 ----此时用brk
64k Delete前内存占用:
64k Delete后内存占用:
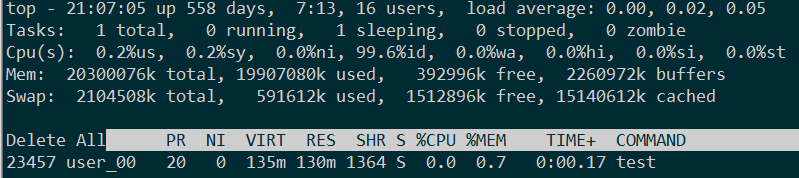
128k Delete前内存占用:
128k Delete后内存占用:
测试代码如下:
int main(int argc, char *argv[])
{
mallopt(M_MMAP_THRESHOLD, 256*1024);
//mallopt(M_TRIM_THRESHOLD, 64*1024);
//MemoryLeak
int MEMORY_SIZE = hydra::CTrans::STOI(argv[1]);
vector<char *> Array;
for (int j=0; j<2064; j++) {
char *Buff = new char[MEMORY_SIZE];
for (int i=0; i<MEMORY_SIZE; i++)
Buff[i] = i;
Array.push_back(Buff);
}
sleep(10);
for (int j=0; j<2065; j++)
delete []Array[j];
cout << "Delete All" << endl;
//sleep(10);
//malloc_trim(0);
//cout << "strim" << endl;
while(1) sleep(10);
}
一个例子来说明内存分配的原理
情况下、malloc小于128k的内存,使用brk分配内存,将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系),如下图:
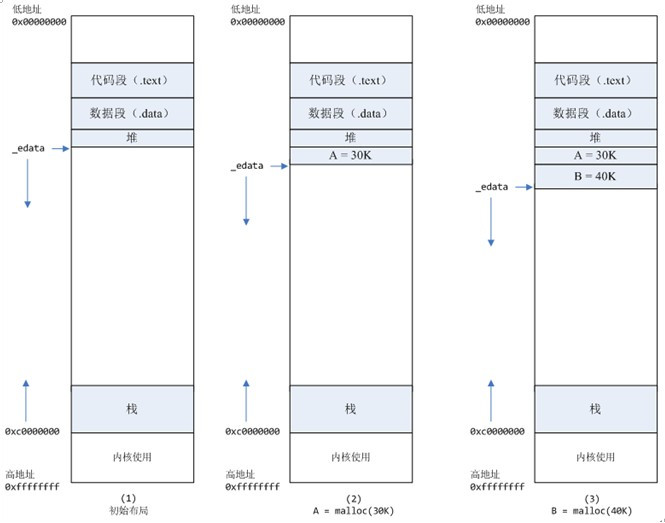
1.进程启动的时候,其(虚拟)内存空间的初始布局如图1所示。
其中,mmap内存映射文件是在堆和栈的中间(例如libc-2.2.93.so,其他数据文件等),为了简单起见,省略了内存映射文件。
_edata指针(glibc里面定义)指向数据段的最高地址。
2.进程调用A=malloc(30k以后,内存空间如图2:
malloc调用会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配。
你可能会问:只要把_edata+30K就完成内存分配了?
事实是这样的,_edata_30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
3.进程调用B=malloc(40K)以后,内存空间如图3.
情况二、malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0),如下图:
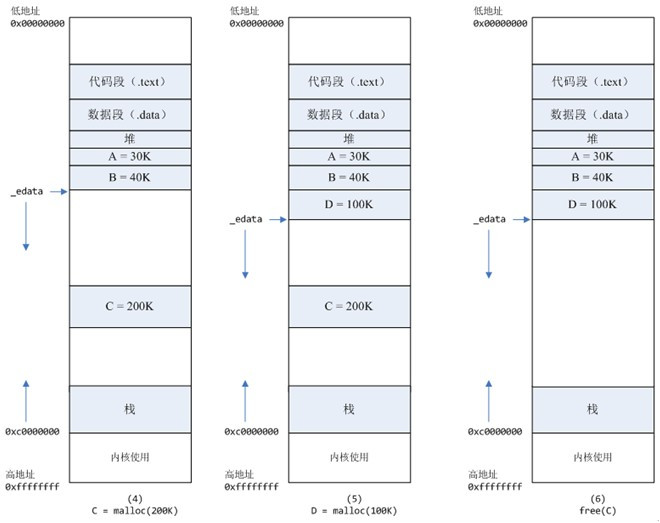
4.进程调用C=malloc(200K)以后,内存空间如图4:
默认情况下,malloc函数分配内存,如果请求内存大于128k(可由M_MAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存。
这样子做主要是因为::brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,这就是内存碎片产生的原因,什么时候紧缩看下面),而mmap分配的内存可以单独释放。
当然,还有其他的好处,也有坏处,再具体下去,有兴趣的同学可以去看glibc里面malloc的代码了。
5.进程调用D=malloc(100K)以后,内存空间如图5;
6.进程调用free©以后,C对应的虚拟内存和物理内存一起释放。
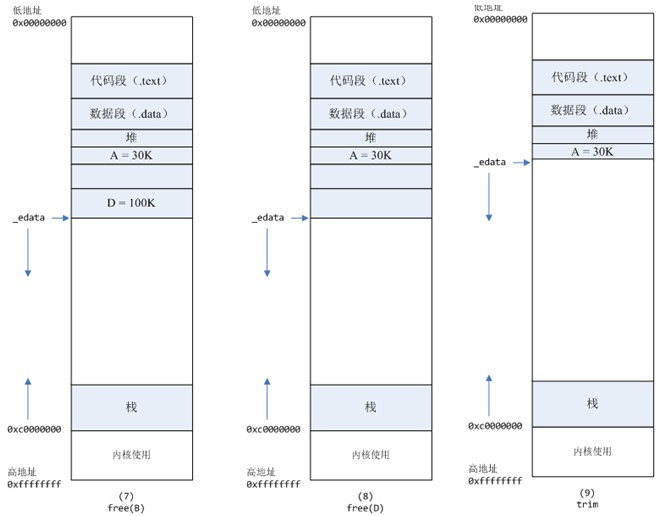
7.进程调用free(B)以后,如图7所示:
B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了。
8.进程调用free(D)以后,如图8所示:
B和D连接起来,变成了一块140K的空闲内存。
9.默认情况下:
当最高地址空闲的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
结论
简单来说,文章开头内存不断增长的趋势的根本原因是:glibc在利用操作系统的内存构建进程自身的内存池。由于进程本身处理请求量大,频繁调用new和delete,在一段时间内,进程不断的从操作系统获取内存来满足新增的调用要求,但是从最终结果上来将,总有一个临界点,使得进程从操作系统新获取的内存和归还操作系统的内存达成相对平衡。在这个动态平衡建立前,内存会不断增长,直到到达临界点。
按照这里理论,机器内存应该先涨后平。我们看下几天后,机器的内存趋势图:
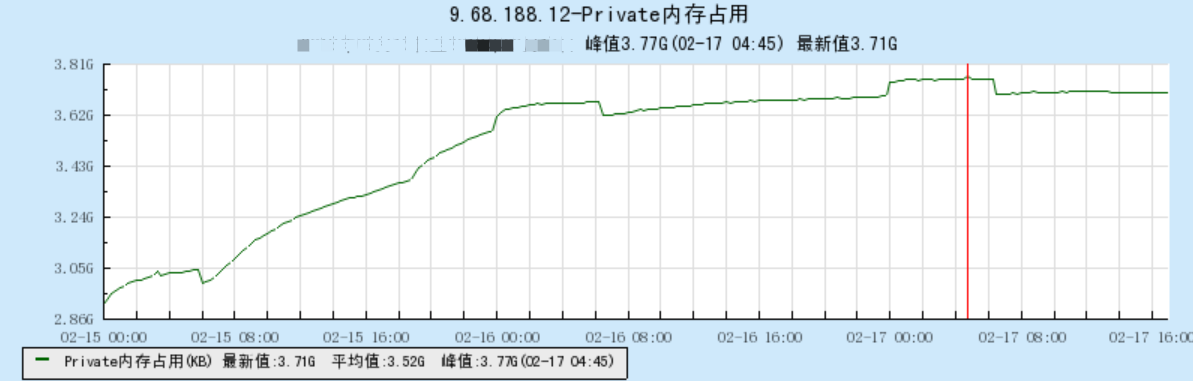
可以看出,在系统内存增长到3.7G左右时,整个机器的内存处于动态平衡的阶段,不再显著增长。由此验证,我们的推断是正确的。
经验
遇到如文章开头所说的那种内存不断增长的情况,不要轻易断定内存泄漏,先观察一段时间再说。很可能是上文分析的原因。

